C:\Users\cy>ssh [email protected] The authenticity of host '124.70.xxx.xxx (124.70.xxx.xxx)' can't be established. ECDSA key fingerprint is SHA256:niKW2UdeZOz5jDXQSbmpHY1vFt******************. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added '124.70.xxx.xxx' (ECDSA) to the list of known hosts. [email protected]'s password:
Welcome to Huawei Cloud Service
[root@ecs-****-0002 ~]#
下载所需软件
下载Hadoop
1 2 3 4 5 6 7 8 9
[root@ecs-****-0002 ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz --2022-12-30 12:10:51-- https://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz Resolving archive.apache.org (archive.apache.org)... 138.201.131.134, 2a01:4f8:172:2ec5::2 Connecting to archive.apache.org (archive.apache.org)|138.201.131.134|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 244469481 (233M) [application/x-gzip] Saving to: ‘hadoop-2.8.3.tar.gz’ 5% [===> ] 14,147,584 295KB/s eta 4m 21s
[root@ecs-****-0001 .ssh]# ssh ecs-****-0002 The authenticity of host 'ecs-****-0002 (124.70.***.***)' can't be established. ECDSA key fingerprint is SHA256:******************************************. ECDSA key fingerprint is MD5:**:**:**:**:**:**:**:**:**:**:**:**:**:**:**:**. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'ecs-****-0002,124.70.***.***' (ECDSA) to the list of known hosts. Last failed login: Sat Dec 31 15:22:29 CST 2022 from 68.183.***.*** on ssh:notty There were 5 failed login attempts since the last successful login. Last login: Sat Dec 31 14:52:26 2022 from 223.90.***.***
**************** for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do if [ -r "$i" ]; then if [ "${-#*i}" != "$-" ]; then . "$i" else . "$i" >/dev/null fi fi done
unset i unset -f pathmunge
export JAVA_HOME=/usr/lib/jvm/jdk8u191-b12 #添加该行
确认java版本
1 2
source /etc/profile java -version
1 2 3 4 5
[root@ecs-****-0001 jvm]# java -version openjdk version "1.8.0_232" OpenJDK Runtime Environment (build 1.8.0_232-b09) OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode) [root@ecs-****-0001 jvm]#
搭建Hadoop集群
在node1节点解压Hadoop安装包
1 2 3 4
cd /root cp hadoop-2.8.3.tar.gz /home/modules/ cd /home/modules/ tar zxvf hadoop-2.8.3.tar.gz
配置Hadoop环境变量
1
vim /home/modules/hadoop-2.8.3/etc/hadoop/hadoop-env.sh
末尾添加
1
export JAVA_HOME=/usr/lib/jvm/jdk8u191-b12
1 2 3 4 5 6 7 8 9 10
# The directory where pid files are stored. /tmp by default. # NOTE: this should be set to a directory that can only be written to by # the user that will run the hadoop daemons. Otherwise there is the # potential for a symlink attack. export HADOOP_PID_DIR=${HADOOP_PID_DIR} export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER export JAVA_HOME=/usr/lib/jvm/jdk8u191-b12 #添加该行
info 各xml配置
修改Hadoop core-site.xml配置文件
1
vim /home/modules/hadoop-2.8.3/etc/hadoop/core-site.xml
........................................ 22/12/31 17:52:29 INFO common.Storage: Storage directory /home/modules/hadoop-2.8.3/tmp/dfs/name has been successfully formatted. 22/12/31 17:52:29 INFO namenode.FSImageFormatProtobuf: Saving image file /home/modules/hadoop-2.8.3/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 22/12/31 17:52:30 INFO namenode.FSImageFormatProtobuf: Image file /home/modules/hadoop-2.8.3/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds. 22/12/31 17:52:30 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 22/12/31 17:52:30 INFO util.ExitUtil: Exiting with status 0 22/12/31 17:52:30 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1 ************************************************************/ [root@ecs-****-0001 jvm]#
node1 执行 start-dfs.sh 启动HDFS
发现警告信息
1
22/12/31 18:07:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
缺少native-hadoop library ,事实上这个警告信息应该没有影响
继续执行hdfs命令
1 2
hdfs dfs -mkdir /bigdata hdfs dfs -ls /
1 2 3 4 5 6
[root@ecs-****-0001 ~]# hdfs dfs -mkdir /bigdata 22/12/31 18:19:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable [root@ecs-****-0001 ~]# hdfs dfs -ls / 22/12/31 18:19:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items drwxr-xr-x - root supergroup 0 2022-12-31 18:18 /bigdata
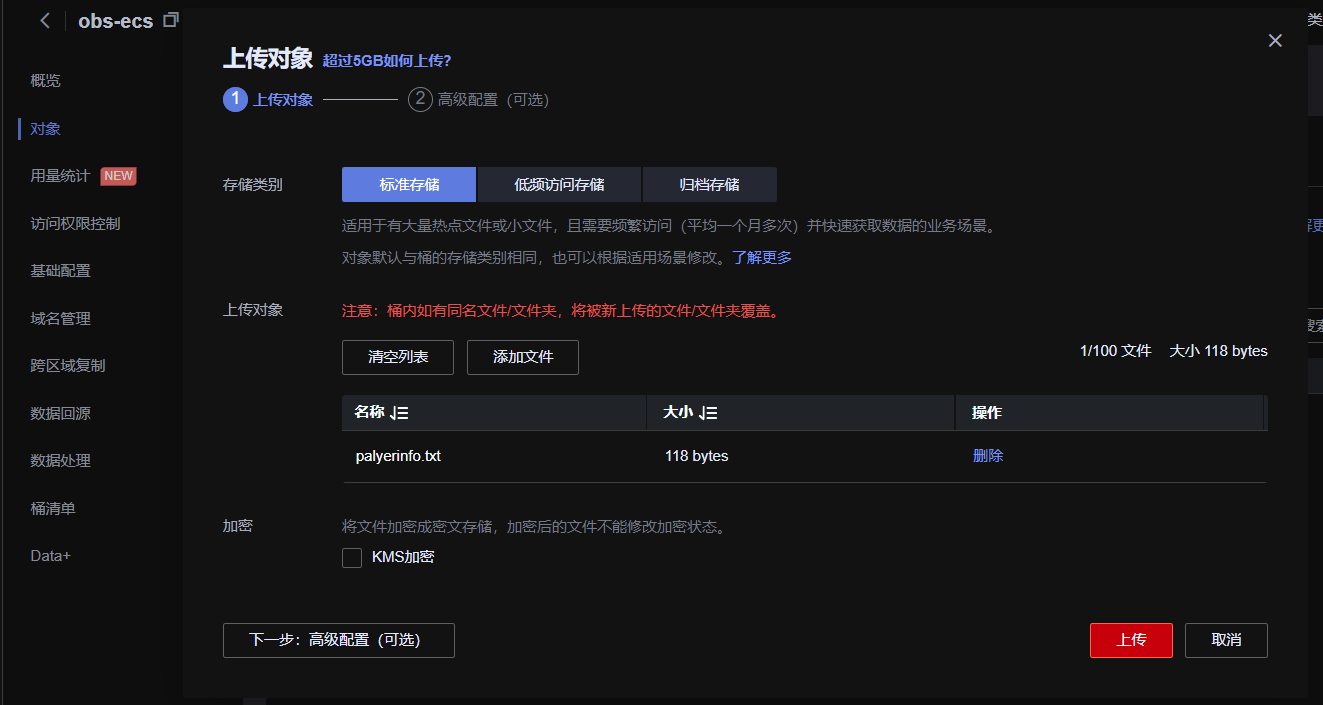
hadoop jar /home/modules/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount obs://obs-ecs/ /output
danger 出现了如下错误 There are 0 datanode(s) running and no node(s) are excluded in this operation.
1 2 3 4 5 6 7 8
................................. 22/12/31 19:20:15 WARN hdfs.DataStreamer: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /tmp/hadoop-yarn/staging/root/.staging/job_1672483928513_0004/job.jar could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1726) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:265) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2561) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:829) ................................