LLaVA 与ollama+open webui部署实战
1. Paper
LLaVA: Visual Instruction Tuning(https://arxiv.org/abs/2304.08485)
LLaVA(Large Language and Vision Assistant, github: https://github.com/haotian-liu/LLaVA)是一种将视觉和语言模型结合起来的多模态模型。LLaVA主要通过视觉指令调优(Visual Instruction Tuning)来实现模型的训练和优化。
1.1 模型架构
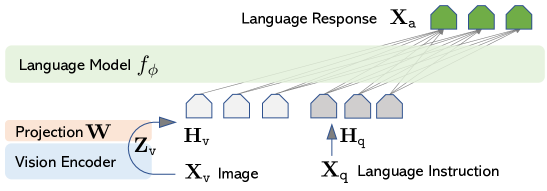
LLaVA的主要目标是有效地利用预训练LLM模型和视觉模型的能力,模型架构如图,其使用 Vicuna 作为 𝜙 参数化的LLM 𝑓𝜙(⋅),因为Vicuna的checkpoint具有最好的语言任务指令跟踪能力。
对于输入图像 ,LLaVA使用预训练的 CLIP 视觉编码器 ViT-L/14 ,它提供了视觉特征 $𝐙_v=𝑔(𝐗_v) $。考虑到最后一个 Transformer 层之前和之后的网格特征,LLaVA使用了一个简单的线性层,将图像特征连接到词嵌入空间中。具体来说,使用了一个可训练的投影矩阵 来将转换到语言嵌入token ,这些token与语言模型中的词嵌入空间具有相同的维度:
由此得到一系列视觉token 。
1.2 数据生成与处理
为了生成指令跟随数据,LLaVA利用了语言模型(如GPT-4或ChatGPT),创建了包含视觉内容的指令数据。这些数据分为三类:对话、详细描述和复杂推理。通过COCO等图像数据集生成了大约15.8万条语言-图像指令数据,其中包括对话、详细描述和复杂推理的问题和答案 。

从表中可以看出,它使用两种类型的符号表示:
(𝑖) 标题
从各种角度描述视觉场景,即以一段自然语言来描述视觉场景;
(𝑖𝑖) 边界框
定位场景中的对象,每个框对对象概念及其空间位置进行编码,就像常规的视觉检测数据集。
1.3 训练过程
LLaVA的训练过程包括对语言模型进行指令调优(Instruction Tuning),利用预训练的视觉模型和语言模型,通过多轮对话数据来优化模型的响应能力。所有的回答被视为助理的响应,形成统一的多模态指令跟随序列 。
对于每张图片 ,其生成多回合对话数据 ,其中 𝑇 是总回合数。将所有对话组织成一个序列,所有答案视为助手的响应,并将 𝑡 第 - 轮的指令 视为:
 (2)
(2)
这样做使得多模态的指令跟随序列的格式进行了统一,于是,便可以使用原始的自回归训练方法,对LLM的预测token进行指令微调(instruction-tuning )。
用于训练模型的输入序列如下,这里只展示了两轮对话,实际上的对话论数根据指令跟随的数据而变化。

与Vicuna-v0相同,LLaVA也设置了system message ,并且设置 <STOP> = ### 。模型通过训练来预测辅助答案和停止位置,因此在自回归模型中只使用绿色 sequence/tokens 来计算损失。
具体来说,对于长度 𝐿 序列,其通过以下方式计算目标答案 的概率:
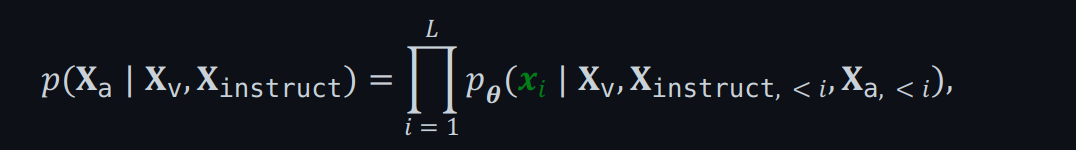 (3)
(3)
其中 是可训练参数, 分别 是当前预测token之前所有回合的指令和应答token 。(预测结果的概率等于每次预测token概率的连乘)
特征对齐的预训练
为了构造的输入 ,对于图像 ,随机抽取一个问题 作为一个语言指令,要求助手简要描述图像,而真实预测答案 是图像的原始标题。LLaVA在训练中冻结了视觉编码器和LLM权重,并仅使用可训练参数 (投影矩阵)以最大化 (3) 的概率。通过这种方式,图像特征 可以与预训练LLM的词嵌入对齐。
这个阶段可以理解为冻结的LLM训练一个适配的视觉分词器。
端到端微调
始终保持视觉编码器权重冻结,并继续更新投影层和LLaVA 中的预训练LLM 权重,即(3) 中的可训练参数 𝜽={𝐖,𝜙} 。
1.4 评估与结果
LLaVA在多个基准测试中表现出色。例如,在12个基准测试中,LLaVA在11个测试中取得了最佳成绩,仅在一个测试中排名第二 。通过调整视觉-语言连接器(如使用两层MLP替代线性投影),LLaVA的多模态能力得到了显著提升。
1.5 优化与改进
LLaVA的研究还探索了不同设计选择的影响,例如跳过初始连接器预训练对模型性能的影响,发现预训练连接器对于模型性能至关重要。此外,LLaVA还利用相关性图(relevancy maps)可视化模型的注意力,帮助理解模型在处理视觉输入时的关注点。
综上所述,LLaVA通过结合视觉和语言模型,并利用大规模的指令数据进行调优,显著提升了多模态模型的性能和响应能力。这一方法展示了在视觉-语言结合领域的巨大潜力和应用前景。
2.部署
2.2 Ollama 与 open WebUI Docker部署
使用docker compose来部署服务
1 | services: |
使用docker compose up -d来部署服务,等待部署完成,访问http://127.0.0.1:3000/即可进入WebUI界面。
2.1 模型下载
2.1.1 ollama社区模型
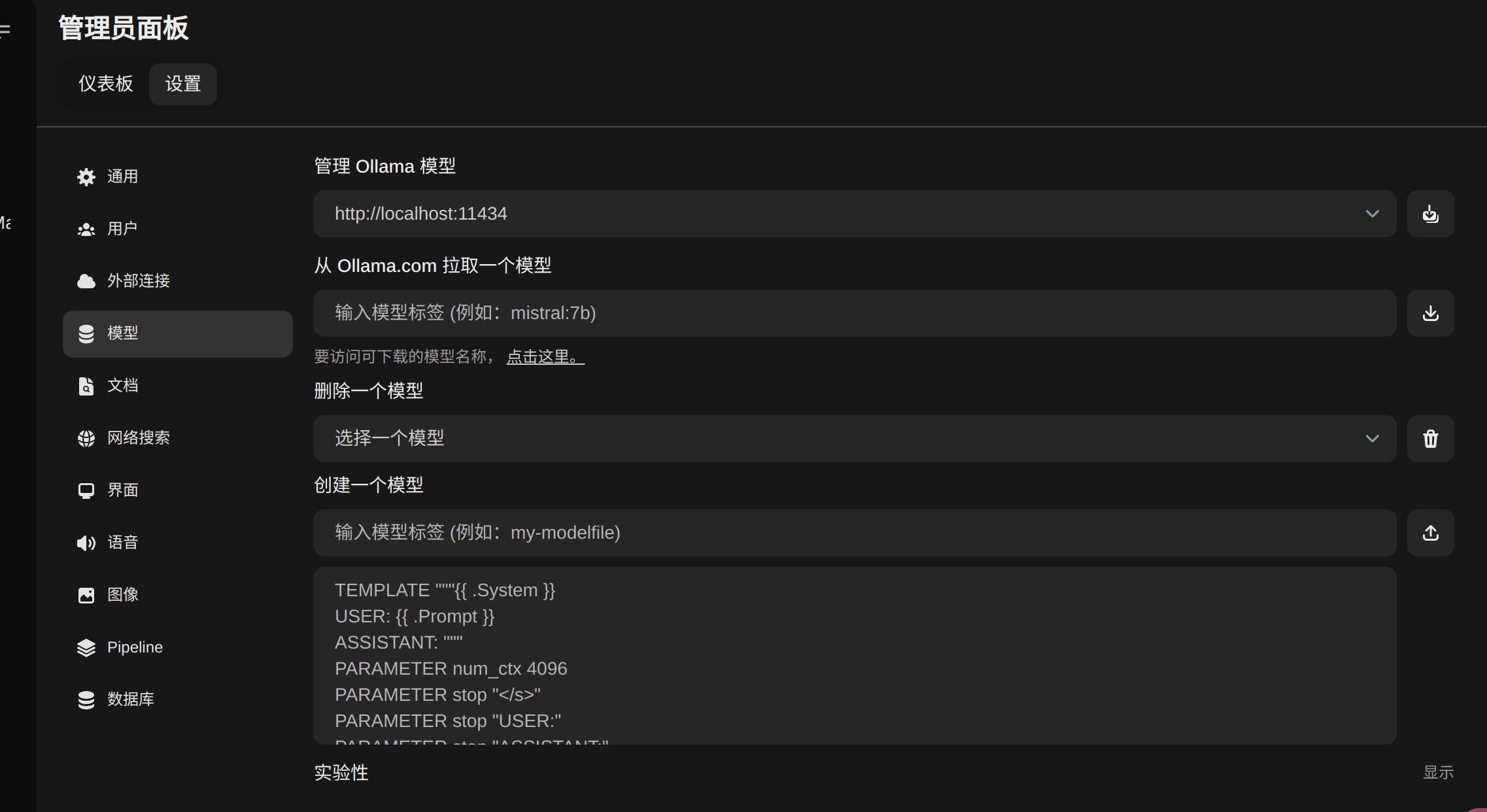
创建完账号之后直接在管理员面板拉取模型,也可以在容器内通过命令行ollama pull llavaL:13b-v1.6-vicuna-q5_K_M来拉取。
2.1.1 自定义模型
使用snap_download从huggingface下载模型,选择的版本为llava-v1.6-mistral-7b。
注:这里下载的是别人量化过的gguf文件,如果要自定义模型,需要自己使用llama.cpp进行编译量化
1 | from huggingface_hub import snapshot_download |
在容器内创建llava.Modelfil:
1 | FROM /path_to_model/llama3-llava-next-8b-gguf/llama3-llava-next-8b-Q8_0.gguf |
使用命令行创建模型ollama create llava -f llava.Modelfile,执行结束后即可在webui中找到创建好的模型。


