Quiet-STaR:让语言模型在“说话”前思考
Quiet-STaR:让语言模型在“说话”前思考
1. 背景
1.1 CoT与StaR
通过生成中间推理步骤(rationale),可以显著提高大型语言模型(LLM)在复杂推理任务(如数学、常识性问答)中的表现。比如“思维链”,但是它需要构建大量基本原理(思考过程)数据集,或者需要使用牺牲准确性的few-shot方式。
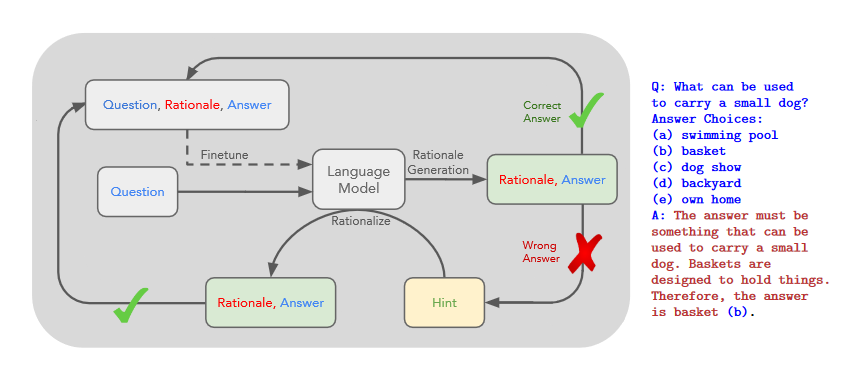
"Self-Taught Reasoner" (STaR) 自学推理机 技术采用了一种迭代自我增强的策略,利用少量理由样例和大量无理由的数据集,不断提升模型的复杂推理能力。核心流程如下:
-
通过小样本提示LLM生成回答的理由。
-
如果生成的答案错误,给模型提供正确的答案,重新生成理由。
-
将正确生成的理由加入到微调数据集。
-
不断重复该过程。
1.2 StaR存在的问题
STaR 通过从问答中的少数例子中推断基本原理并从那些导致正确答案的例子中学习,使得大语言模型可以通过利用其自身的推理能力来改进自身。
STaR证明了:语言模型可以通过采样理由来尝试回答问题,并带着理由进行训练,可增强其在问答(QA)数据集上的推理能力,但也存在如下缺陷:
-
其侧重于于单个任务或预定义的任务集
-
其推理任务需要针对提供的答案-原因对数据集,也就是依赖提供的数据集去构建推理任务。
-
人为策划的QA数据集限制了其基本原理的规模和普遍性。
理想情况下,语言模型应当可以学习推断任意文本中未阐明的基本原理,而不依赖于特定的QA数据集。针对上述问题,文章提出了Quiet-STar方法。
2. Quiet-StaR方法
2.1 概述
Quiet-STaR扩展了STaR,该方法训练LM来生成推理内容,帮助它从大型互联网文本语料库中推断出未来的文本,允许LM从各种任务中学习,而不仅是数学QA或特定推理任务。其利用语言模型预先存在的推理能力来生成基本原理,并基于强化学习方法的奖励来训练语言模型。
该方法让LM学习每个token生成的基本原理来解释未来的文本,从而改进其预测。可以理解为“安静地”应用STaR,训练模型在说话(输出文本)前先思考。
2.2 基本思想
模型在预测每一个token之前,就先输出固定长度的思考内容,然后再基于思考的内容进行下一步预测。
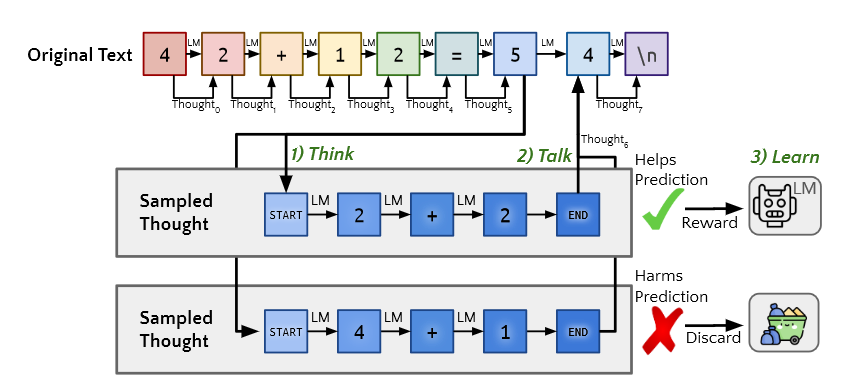
大体来说,其做法是:首先在每个token生成后,生成一串基本原理token来解释未来的文本(think),将带有想法和不带有想法的下一个预测token进行混合(talk),然后使用REINFORCE增加有助于模型预测未来文本的想法的可能性,同时丢弃使未来文本不太可能出现的想法(learn)。
-
思考(Think) 并行理由生成
并行为每个token分别生成多个可能的“思考”序列,输入为整个训练句子,每个token的思考序列数量r,每条思考序列的长度t,其中n为token数量。
每个token的多个思考序列之间使用<开始思考>和<结束思考>token包围,这些token也是可学习的嵌入向量。
-
表达(Talk),混合带有理由预测和基础预测
使用模型生成的思考来预测下一个token,并与原始预测token进行混合,生成最终的输出。这个混合过程由一个浅层MLP组成的“混合头”(Mixing Head)控制,它学习如何更好地结合思考前后的预测结果。
-
学习(learn),优化理由生成
使用强化学习算法来优化思考过程,如果某个思考序列能够提高后续文本预测准确率,那么生成这个序列的概率就会增加,循环这个过程,使得语言模型能够逐步提升自己的推理能力,该过程不仅预测接下来的一个token,而是预测接下来的多个token。
2.3 具体工作流
1.原始文本(Origin Text)
原始文本输入序列: 4 2 + 1 2 = 5 4 \n, 输入序列长度n为9。
2.思考过程(Think)
指定超参数来表示生成的“思考”序列数量,并行为每个token分别生成多个可能的“思考”序列,其中每个序列以<START>开始,以<END>结束,中间是语言模型生成的token。
3.采样想法(Sampled Thought)
使用生成的思考序列来预测下一个token,图中生成了两个序列:
序列2 + 2有助于预测下一个token,而序列4 + 1对于预测没有帮助。
4.学习过程(Learn)
有助于预测的思考会得到奖励(绿色√),从而增加这种思考序列生成的概率,而没有帮助或有害的思考则会被丢弃(红色×),从而降低类似思考产生的概率。
5.模型更新
基于这个奖励/惩罚机制,语言模型不断更新,学习生成更有帮助的思考。这个过程允许模型通过生成内部“思考”来改善其预测的能力,而不需要外部监督。模型可以通过尝试不同的思考并评估它们的有用性来“自学”更好的推理策略。
3. 技术细节
3.1 问题描述
Quiet-STaR 在序列的每一对观测token之间引入一个辅助的"理由"变量,其目标是优化一个参数为θ的语言模型,该模型具有生成中间思想(或理论基础)的能力,使得
其中n为输入序列长度。
也就是说,通过找到参数 θ,使得在给定输入序列和基于该序列生成理由的情况下,生成后续序列的概率最大化。
3.2 存在的挑战与解决方案
Quiet-STaR 需要在输入序列的每个token位置高效地生成推理,且每个令牌单独的前向传递,这对于长序列来说在计算上变得难以处理。
也就是说,对于一个输入序列,模型不仅要预测下一个token,还需要根据当前位置之前的token生成一个推理序列,这个过程增加了额外的计算开销。
针对这个问题,Quiet-STaR使用了并行采样算法。
3.2.1 并行采样算法
语言模型会在推理的过程中为所有输入token生成下一个token的分布,这允许模型为每个token采样一个后续token。比如输入序列为<bos> the cat sat,对于其中的每个token,可能会生成下面的预测yes、orange、saw 、down,每个后继token本身对于序列前缀来说都是一个合理的下一个token。
首先,我们知道Masked Self-attention的权重为如下所示的形式
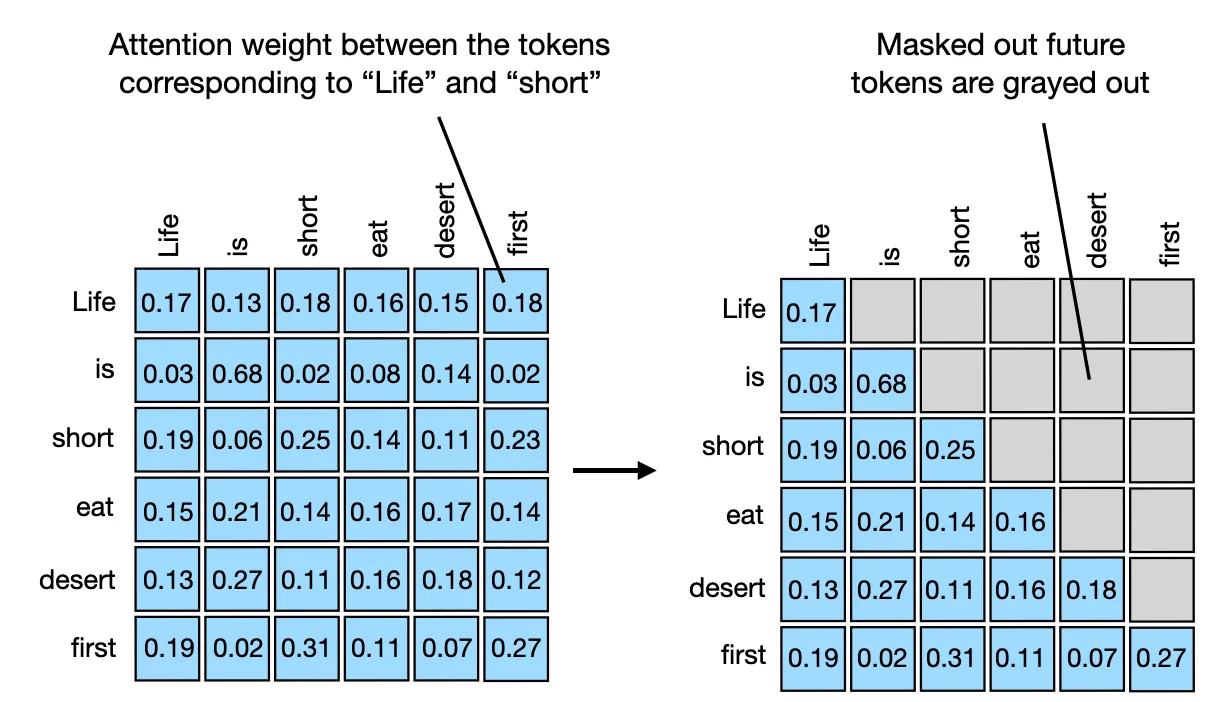 Attention在经过Mask后,只有一部分被保留。也就是下面右图中的左上部分。
Attention在经过Mask后,只有一部分被保留。也就是下面右图中的左上部分。
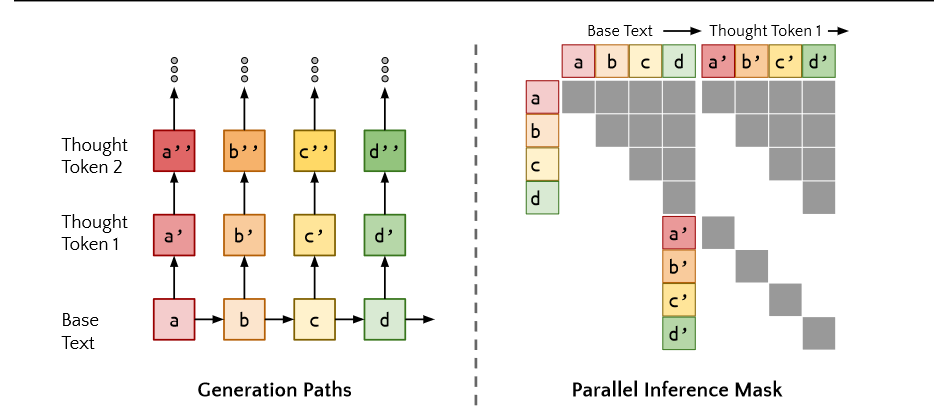
Quiet-STaR缓存每个前向传递的结果,将一个对角线注意力掩码串接到前一个注意力掩码上,每个生成的想法token只需要计算用于它与生成它路径token的注意力,以及和它自己的注意力,而不需要计算其他路径上token的注意力。如图所示,如果我们输入序列为a b c d,即序列长度n=4,理由采样数量r为1,那么会产生个想法通路,每个想法通路的长度为t(t>2)。
这个过程一共需要得到$$n × r = 4$个token序列,直接按照原来的attention计算方式会对每个通路进行单独计算,这会带来计算量的浪费。然而,我们可以缓存a->b->c->d 的生成路径,于是便可以直接得到a' b' c' d'四个token(因为a'和b都是a生成token的候选),这样就分别得到了a、b、c、d第一个thought的第一个token。然后,我们通过计算a b c d序列的masked self-attention,它们和a' b' c' d'的masked atttion,以及a' b' c' d'各自对自身的self-attention,就得到了上面右侧的三个矩阵。对于a的第一个想法路径,其下一个应该是a'',它需要计算的是a a'的masked self-attention,它恰好可以由上面的三个矩阵的一部分拼接而成。


同理,对于b'',我们也可以将a b做attention的结果,拼接上b'与a b的attention和b'对自己的attention得到,c'' d''也是如此。也就是说,我们在得到上面三个矩阵的时候,就同时得到了a'' b'' c'' d''所需要的attention矩阵。通过这种方式,我们在基本序列计算完成之后,就可以立即得到对每个token其中一个采样通路的第一个token,这样就能够完成同时对所有通路进行采样。
3.2.2 混合头
为了平滑向思维过渡,Quiet-STaR在有思维和无思维的预测之间引入了一个学习的插值。给定思考结束token的隐藏状态和原始文本不带thought的CLS token的隐藏状态,混合头输出一个权重,该权重决定了思维后预测logits将被使用的程度。这个头部使用的是一个浅层的多层感知器,为每个token输出一个标量。其作用类似于在语言模型内部的“对话系统”,用于确定是听从带有思考的推理结果还是不带思考的推理结果。对于不同的上下文,混合头可以学会何时更多地依赖思考,合适更多地依赖原始预测。
3.3.3 优化理由生成
Quiet-STaR 将开始和结束标记嵌入初始化为破折号-- 对应的嵌入,其在文本数据中经常出现,表示停顿或想法。这充分利用了语言模型的先验知识。从直观上来看,开始的思想token可以理解为将模型放入"思维模式"中,结束的思想token可以理解为它告诉模型什么时候完成了思考。
3.3.4 非短视评分和Teacher-forcing
非短视评分
由于我们并不期望思考在预测每一个token时都是有用的,因此我们更希望模型的奖励更多地依赖于思考后面的语义内容,而不是依赖于下一个确切的单词。因此Quiet-STaR采用了一种非短视(non-myopic)的损失函数,同时预测多个未来token的同时,模型计算理性思考对接下来n_true个token的预测效果。这样做可以使得模型能更全面评估理性思考的实际作用,而不是仅仅是用于预测下一个token,非短视损失函数也可以捕捉那些不会立即带来好处,但会对预测更远的结果有帮助的token。这种方式提高了Quiet-STaR的性能,特别是在需要进行长序列推理的任务中。
Teacher-forcing
Teacher-forcing是一种在序列生成任务中常见的训练技术,它通过在训练过程中使用真是标签(实际的目的序列)来作为输入,帮助模型更快速地收敛。
比如,给定输入句子“我想吃”,模型需要预测的下一个词可能是“冰淇凌”、“炸鸡”等。如果没有Teacher-forcing,模型会在生成每个词时依赖前一步的输出。如果模型一开始的输出就不准确,那么后续的词也大概率不准确,这种错误会逐渐累积,最终造成预测的词和预期相差甚远。而Teacher-forcing会直接将每一步的真实标签(目的序列中的下一个词)作为下一步模型的输入,从而保证模型不会因为错误累积而无法快速学习到序列关系。
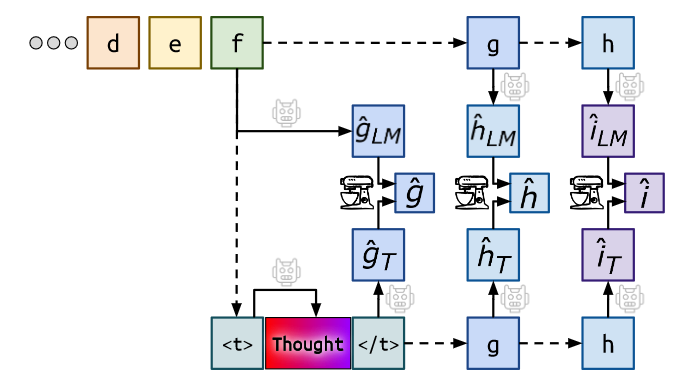 其中实线表示语言模型计算,虚线表示通过Teacher-forcing插入token,搅拌器表示混合头。
其中实线表示语言模型计算,虚线表示通过Teacher-forcing插入token,搅拌器表示混合头。
在并行生成思考时,模型同时从序列的每个位置生成多个思考序列,这些序列与真实序列之间没有直接对应关系,模型无法根据这些生成的序列与真实序列间的差异来更新模型参数。比如对于原始输入序列the cat sat on the mat. ,对于token cat 模型可能会生成下面几个理性思考:Because it is an animal.、Because it is a pet.、Because it is mentioned in the text.。 这些理性思考序列是并行生成的,没有明确的“正确”答案,因为多个理性思考序列都可能合理解释下一个token的出现,传统的反向传播方法就无法直接应用。
为了解决上述问题,Quiet-STaR首先基于当前的理性思考来预测未来的n_true个token,然后通过Teacher-forcing将真实未的未来token作为输入,继续预测更远的未来token。通过该方式,模型可以接收到关于其预测准确性的反馈,避免了生成的thought没有真实标注无法直接通过反向传播梯度的问题,使得模型更倾向于在未来的迭代中生成更有用的思考,并且不会因之前的错误累积影响未来token的预测。
参考文献


