PaddleX在Windows平台的部署
本文基本参照 PaddleX官方部署方式, 只进行paddlex模型的c#端部署和验证,而不进行模型的训练相关操作。
info 目前已经具备的CUDA环境和cuDNN环境情况
1 | C:\Users\cy\paddle_deploy>nvcc --version |
cudnn_version.h中
1 |
当前CUDA版本:11.7,cuDNN版本:8.6.0
需要根据实际情况进行多CUDA环境部署
info 指定的版本 CUDA 11.0 Cudnn 8.0
安装后有两个版本的CUDA
将cudnn压缩包中的文件复制到对应版本的CUDA安装目录
CUDA版本配置完毕
准备工作
下载所需要的各类环境:paddlex和PPdeploy,TensorRT 7.2.3,opencv 3.4.6, PaddleInference release2.3版本,cmake 3.18.5可手动安装,以下为命令行安装方式。关于windows下如何命令行下载安装,请看这里
1 | 下载paddlex和PPdeploy |
运行opencv的自解压程序,解压opencv到当前路径,tree 得到当前目录树
1 | C:\Users\cy\paddle_deploy>tree -L 1 |
在windows环境变量中将opencv的路径 C:\Users\user_name\paddle_deploy\opencv\build\x64\vc15\bin 添加到path
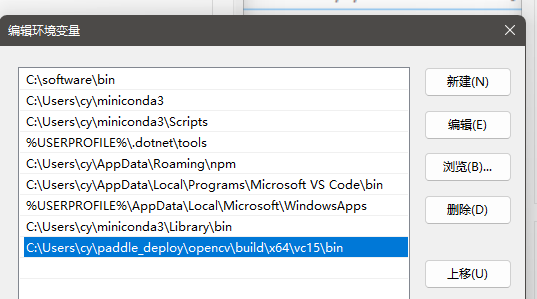
开始编译
替换相关文件
替换model_infer.cpp预测代码
使用 PPdeploy/dlldemo中的model_infer.cpp 和 CMakeLists.txt替换 PaddleX/deploy/cpp/demo/ 中的同名文件
替换相关头文件
将PPdeploy/dlldemo中的 logger.h、model_infer.h、thread_pool.h、timer.h 头文件复制到PaddleX/deploy/cpp/demo/目录下。
使用CMake编译
主要编译 PaddleX/deploy/cpp中的代码,使用out承接编译生成的文件
运行 cmake\cmake-3.18.5-win64-x64\bin\cmake-gui.exe ,手动创建 PaddleX/deploy/cpp/out目录。
源代码路径选择 PaddleX/deploy/cpp目录
输出路径选择 PaddleX/deploy/cpp/out
配置configure
直接进行编译会报错,需要补充一些lib库
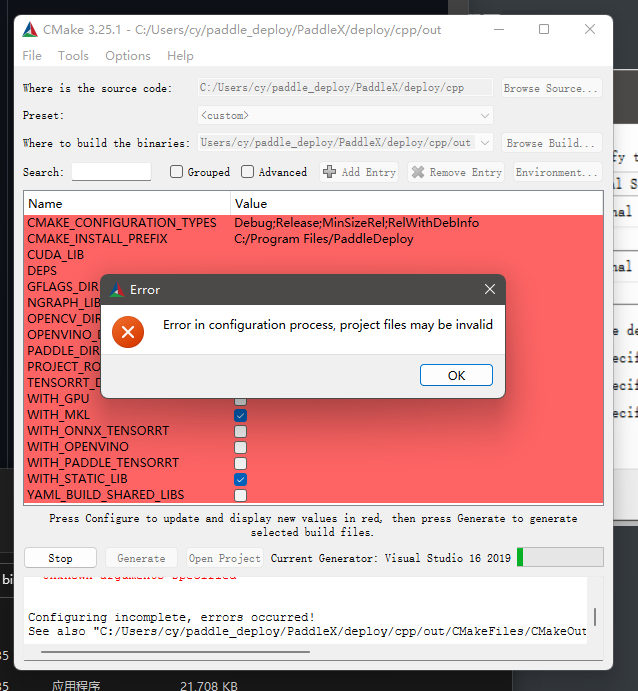
GPU版本
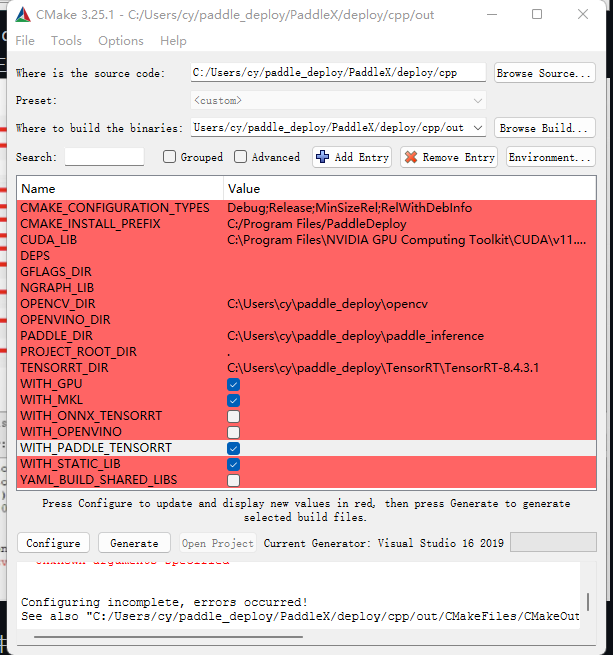
分别填入 CUDA_LIB OPENCV_DIR PADDLE_DIR TENSORRT_DIR,勾选上 WITH_GPU WITH_MKL WITH_PADDLE_TENSORRT WITH_STATIC_LIB,点击 Generate 开始生成。
最终在 Paddle/deploy/cpp/out 目录下生成如下文件
1 | . |
可以看到,出现了 PaddleDeploy.sln文件,则表示通过cmake生成成功了解决方案。
打开 PaddleDeploy.sln ,在VS解决方案管理器中可以看到一些项目
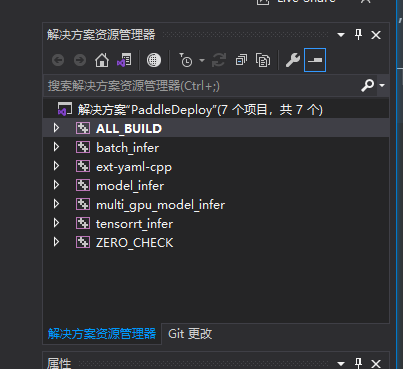
其中,关键的是 model_infer,也是后续C#工程需要直接调用的模块.
后续可能还会用到的几个模块:
批处理推理 batch_infer
多GPU推理(当前用不到) multi_gpu_model_infer
使用TensorRT推理 tensorrt_infer
可能由于版本管理问题,打开项目时会提示有错误,只需要将报错的几行代码注释即可,不影响使用
将项目版本调整成 release,然后生成项目 model_infer
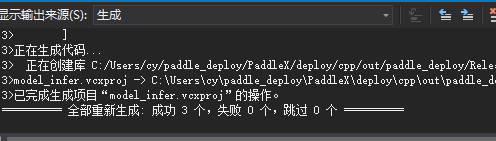
最终在PaddleX\deploy\cpp\out\paddle_deploy目录下生成如下文件
1 | . |
这些文件之后都要复制到c#工程的bin\目录下。
注意:如果编译生成过程中出现 无法打开 源文件 “yaml-cpp/yaml.h"(issues 4),
则需要在上一步生成之前勾选 YAML_BUILD_SHARED_LIBS ,再次生成解决方案。如果这样也不行,则需要自行下载yaml-cpp.zip,将其中的文件解压到PaddleX\deploy\cpp\yaml-cpp\目录中。问题的原因是生成过程中需要下载yaml-cpp并且编译,如果在Makefile中将该路径引入而没有找到相应文件的话就会出现上述错误。
CPU版本
需要下载cpu MKL版本的推理库
编译的时候需要去掉with GPU,其他步骤同上,需要注意的是 PADDLE_DIR的路径应该的cpu版本的推理库路径。
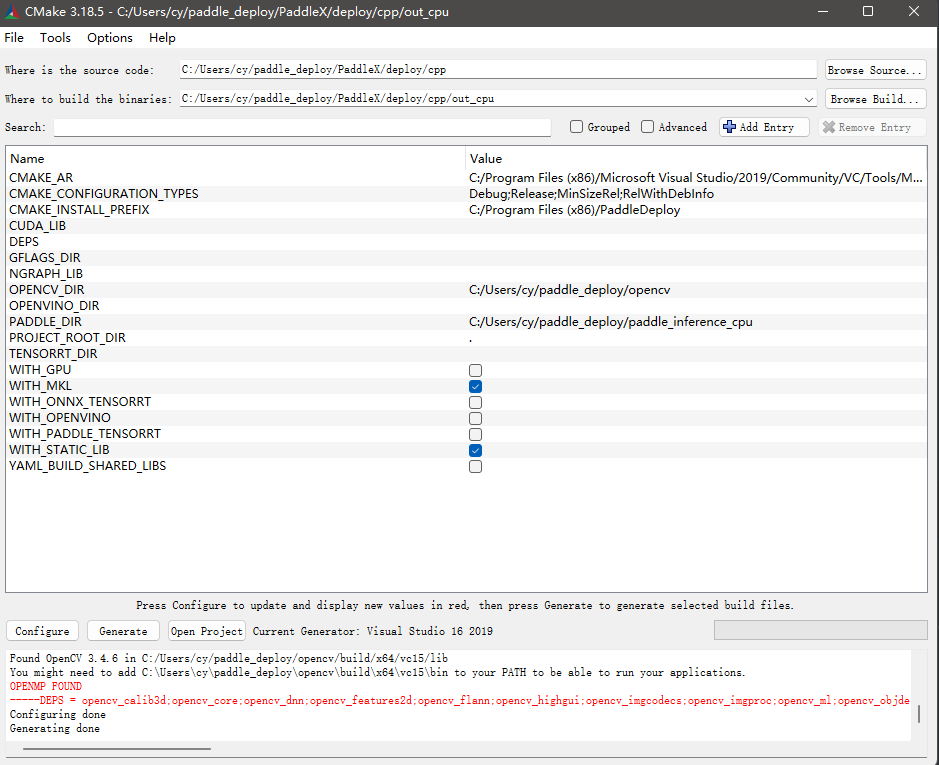
使用cpu推理库时,out_cpu\paddle_deploy下生成的文件略有不同
1 | . |
少了nv相关的文件,并且由于少了GPU的部分,paddle_inference.dll文件的体积小了很多
使用C#项目调用dll
使用官方的Demo
官方给出了一个C#的Demo,位于 PPdeploy\paddlex\deploy\csharp 的 ModelInferUI.sln ,选择Debug X64模式进行调试。调试之前需要确保 bin\x64\Debug下包含以下dll:
-
model_infer.dll, 位于上边cmkae编译的目录下:PaddleX\deploy\cpp\out\paddle_deploy\Release -
其余dll, 位于以下目录:
PaddleX\deploy\cpp\out\paddle_deploy -
paddle2onnx.dll、onnxruntime.dll,位于paddle_inference\third_party\install\paddle2onnxpaddle_inference\third_party\install\onnxruntime文件中 -
OpenCvSharp.Extensions.dll位于libs\opencvsharp453\NativeLib\x64中,移动到bin目录下即可
如果调试的时候提示cv相关的引用报错,可能是由于项目中没有引入opencvsharp的包,需要在Nuget包管理器中添加OpenCvSharp4和OpenCvSharp4.runtime.win 版本号前缀为4.5.3

执行调试就可以看到官方demo的界面
选择对应的模型文件目录和图片文件目录,模型类型根据模型实际情况选择,这里我选择的是paddlex
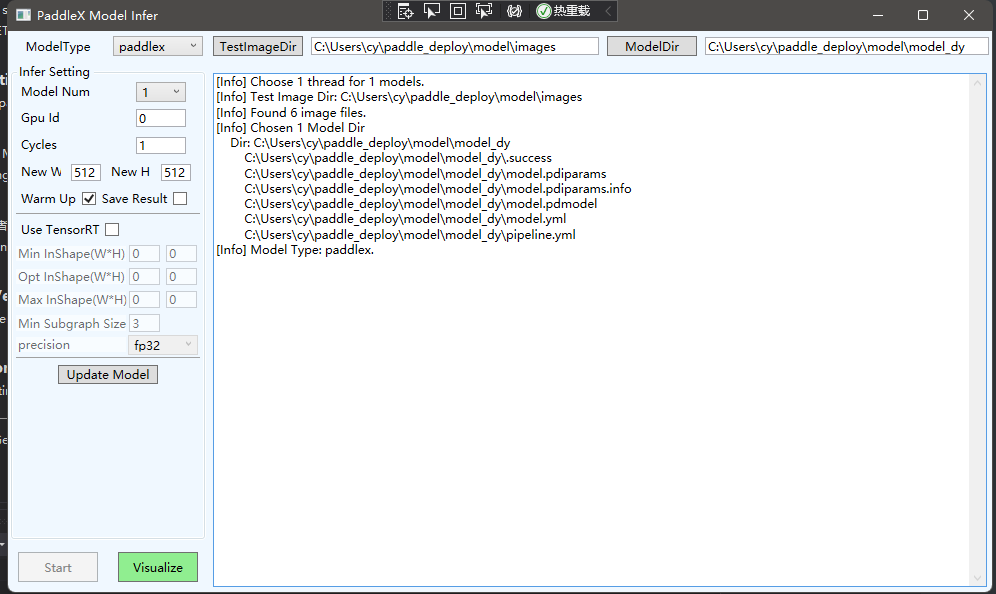
点击Update Model 初始化模型,然后点击start,如果没有出现报错,模型就会开始执行推理
1 | [Info] Finished 1 models warm up with 100 cycles.Warm up Total elapse: 21193 ms, Average elapse: 211 ms. |
这里之所以推理耗时这么久是因为我修改了model_infer项目中的代码,导致现在使用的是cpu模式进行推理(稍后会提到如何修改model_infer中的相关代码来实现在自己的项目中部署paddle)
使用GPU版本的推理库时,可以选择使用GPU/CPU来推理。
在自己的C#中调用paddle
添加引用
首先在nuget包管理中添加OpenCvSharp4和OpenCvSharp4.runtime.win
添加程序集引用 PresentationCore、 PresentationFramework 。
将PPdeploy\paddlex\deploy\csharp\ModelInferUI\libs\opencvsharp453文件夹复制到当前项目的lib\中,然后从文件添加引用OpenCvSharp.Extensions (位于paddle_cshap_demo\paddle_cshap_demo\libs\opencvsharp453\ManagedLib\net461\OpenCvSharp.Extensions.dll)
画出控件
运行库安装
测试模型加载
测试模型推理
模型调用库C#再封装


