Tree Of Thoughts 解读
1. 思维链(Chain Of Thought)
要介绍ToT,首先要介绍下大名鼎鼎的CoT,也就是思维链(Chain Of Thought)。
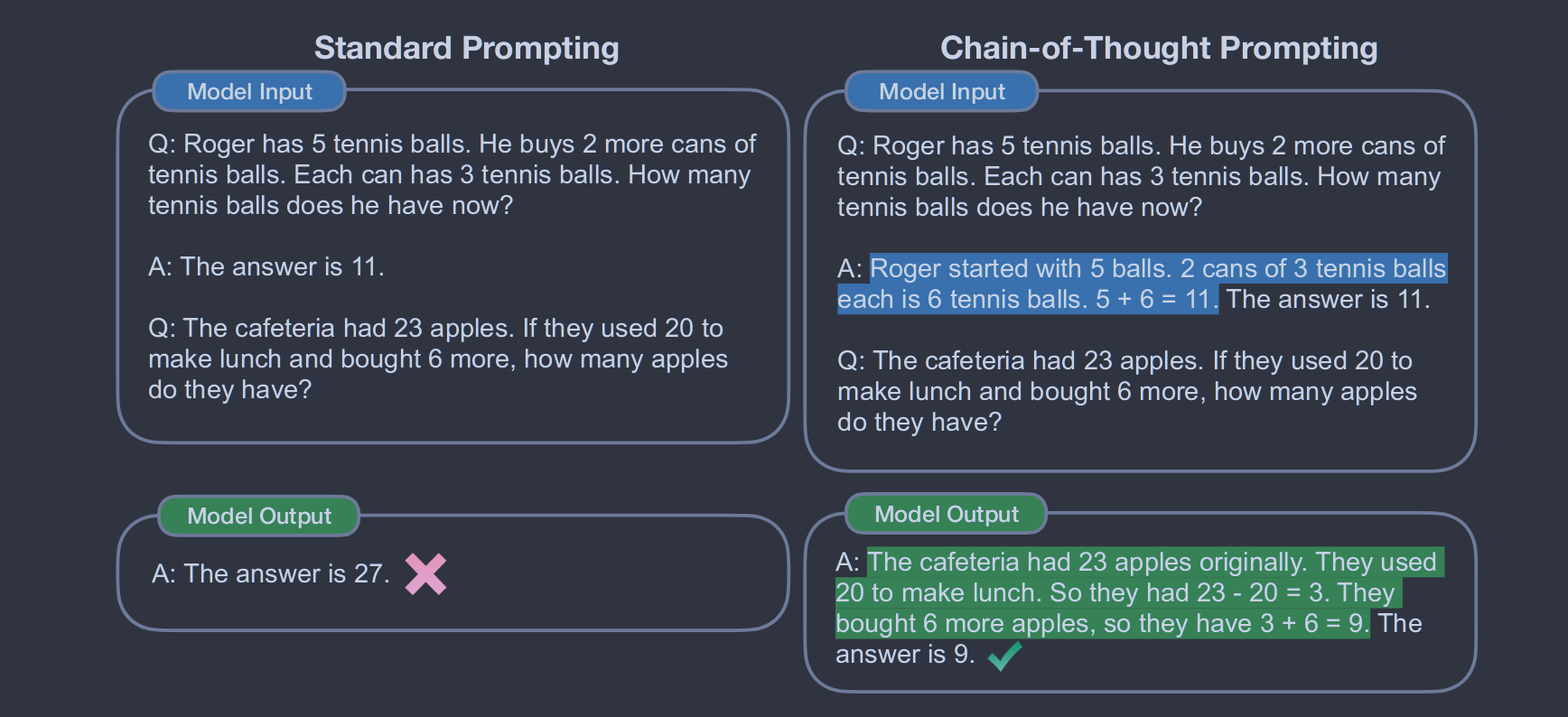
思维链属于**提示词工程(Prompt Engineering)**的一种,其主要思想是通过向大语言模型展示一些少量的样例,在样例中将多步问题分解为中间步骤,通过中间步骤得出最终答案。大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。CoT提示作为一种简单机制,成功引出大型语言模型中的多步推理行为,并在不同任务上表现出强大的性能提升。
我们使用喜闻乐见的一个比大小的例子来测试思维链的做作用。众所周知,强如gpt4这样的模型,面对如11.3和11.11谁更大这种问题时也会出现错误。(当前版本已经被修复了,先前同样的问题得到的答案是11.11>11.3)
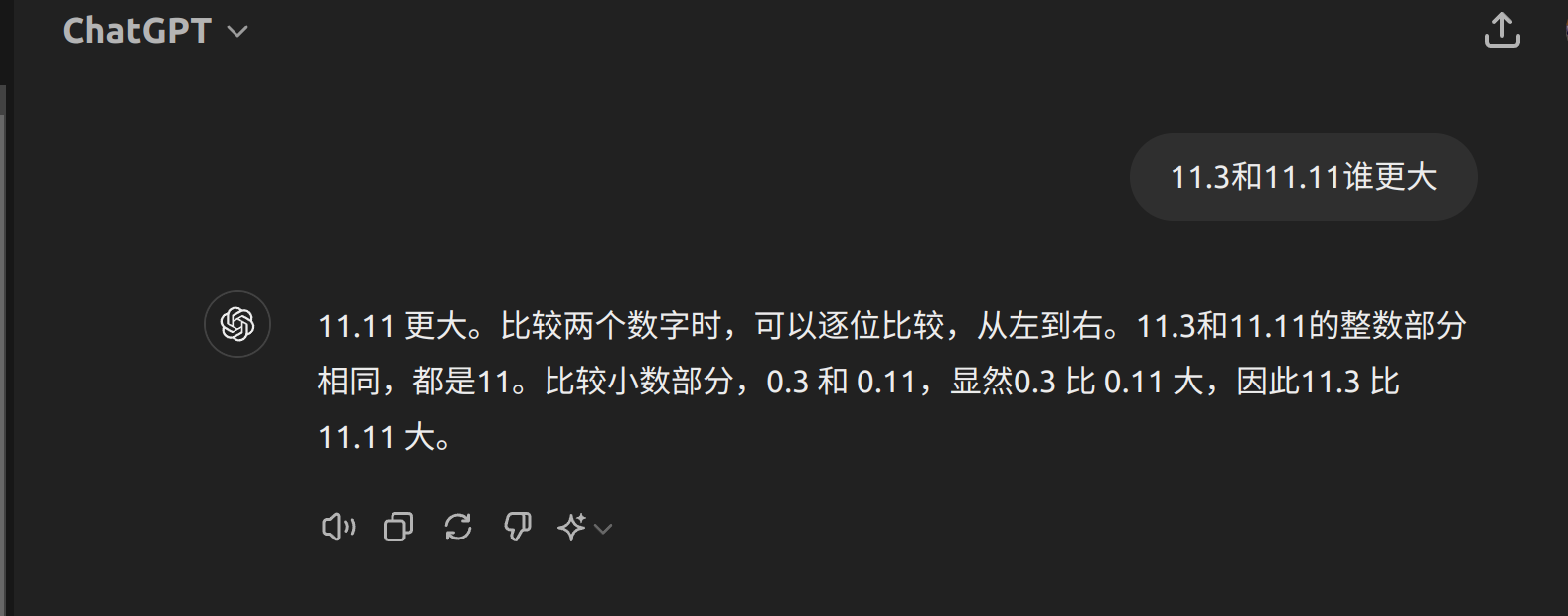
有人分析说其出现的原因是xx.yy这样的数字默认情况下被分词器拆分成了xx,.和yy三个不同的token,而没有当成一个整体。如果我们使用思维链来构建这个问题,就变成了下面的情况:
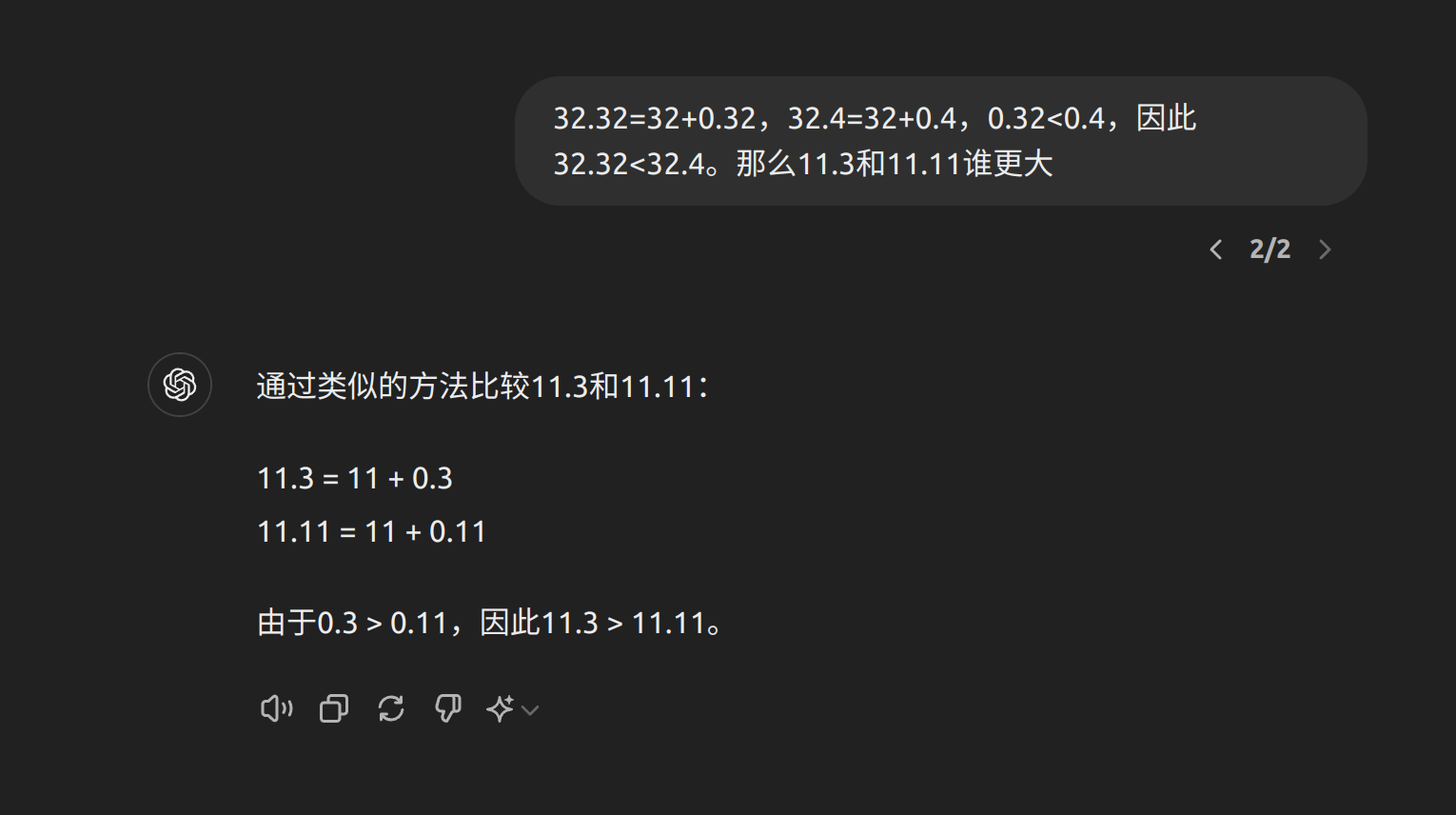
很显然模型根据给出的few-shot提示推理得到了正确的答案,在prompt提示下,模型理解了语句中的.yy是数学中的小数位,而不是附加上的额外数字。
思想链推理是模型规模的一个涌现性质,能够显著拓宽大型语言模型所能执行的推理任务范围。然而根据Wei等人的说法,“思维链仅在使用∼100B参数的模型时才会产生性能提升”。较小的模型编写了不合逻辑的思维链会导致精度比标准提示更差。通常,模型从思维链提示过程中获得性能提升的方式与模型的大小成比例。
2. 零样本思维链(Zero-shot-CoT)与自洽性思维链(Self-Consistency-CoT)
零样本思维链(Zero Shot Chain of Thought,Zero-shot-CoT)提示过程是对 CoT prompting的后续研究,引入了一种非常简单的零样本提示。他们发现,通过在问题的结尾附加“让我们一步步思考。”这几个词,大语言模型能够生成一个回答问题的思维链。从这个思维链中,他们能够提取更准确的答案。
OK,那同样的例子,再使用Zero Shot Chain of Thought,看一下结果。
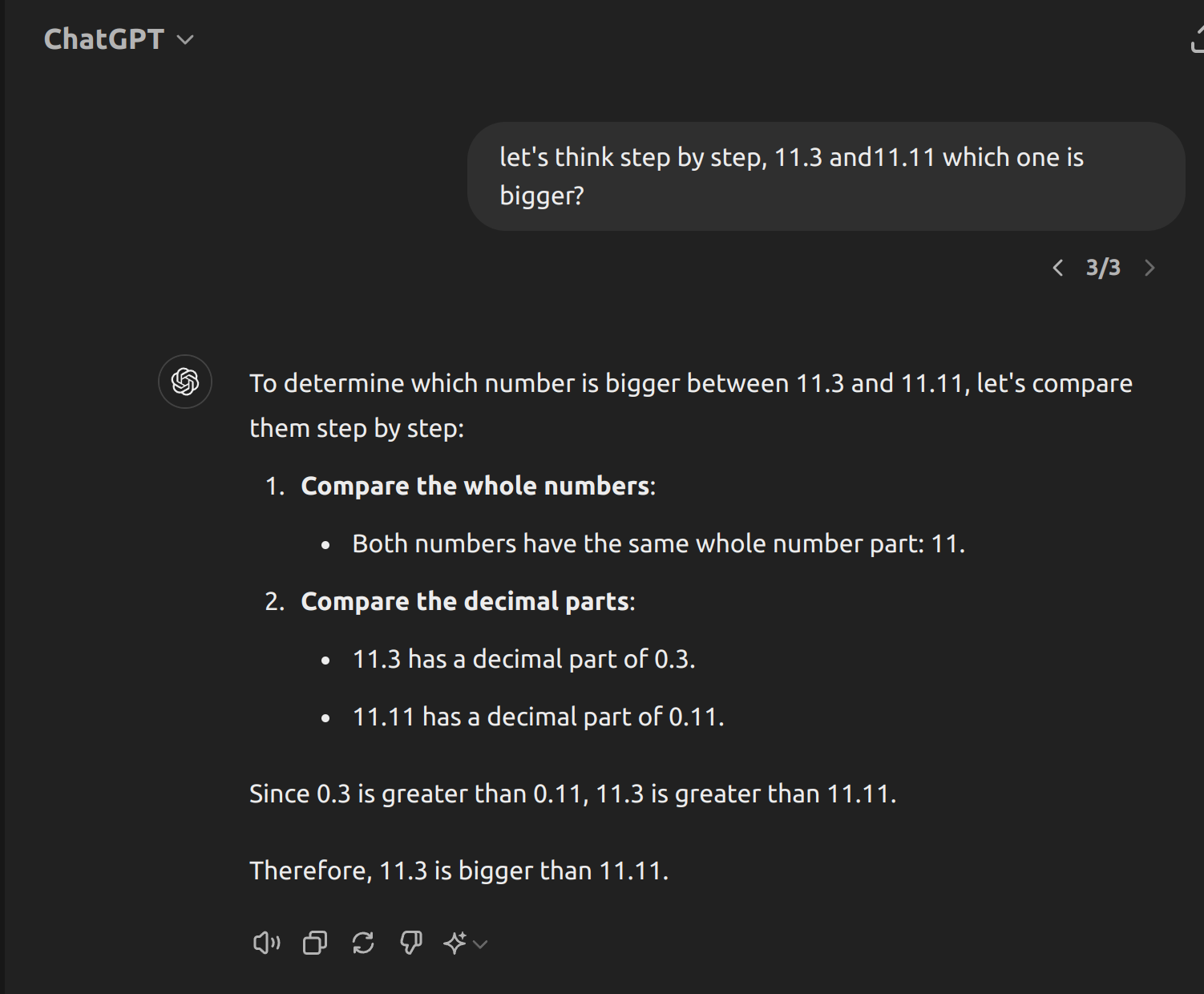
可以看到,当时用let's think step by step后,LLM将其认为是一个数学问题并进行一步步拆分分析,最后推到出正确答案,并且这种方式不需要在提示阶段进行额外的推理提示。
自洽性思维链(Self Consistency Chain of Thought )是从语言模型中采样一组不同的输出,并返回该集中最一致的答案。这种集成方法在与思维链提示相结合时提高了推理的准确性。
例如: INPUT:
1 | “如果有3辆车在停车场,后来又来了2辆车,停车场共有几辆车?” |
通过温度采样(temperature sampling)、top-k采样或核采样(nucleus sampling)等模型生成多个推理路径,如下:
OUTPUT1:
1 | 3辆车在停车场,2辆车到达,共3+2=5辆车。 |
OUTPUT2:
1 | 停车场有3辆车,后来2辆车到达,所以有5辆车。 |
然后对生成的候选答案进行统计,记录每个答案出现的频率,通过对所有采样的推理路径的最终答案进行投票,选择出现频率最高的答案作为最终答案。
当然,以上只是一些常规推理问题,如果是类似于24点(给定4个数字,判断是否能通过加减乘除组合得到24)这种复杂问题,仅仅使用CoT还能否得到正确的答案呢?
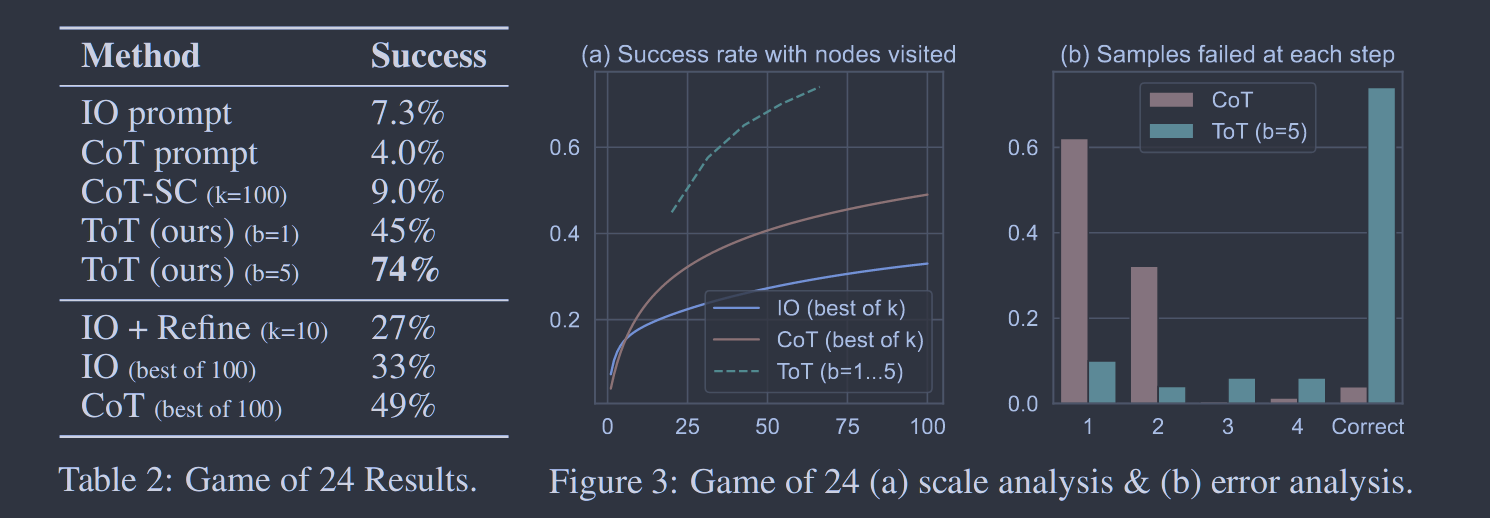
对于这个问题,文章Tree of Thoughts: Deliberate Problem Solving with Large Language Models表示,使用标准CoT提示回答的准确只有4.0%(对应当时版本的gpt-4)。
3. 思维树 Tree of Thoughts
传统的语言模型采用从左到右的token级别决策过程,可能在复杂问题解决中表现不足。ToT框架通过允许语言模型在决策过程中探索多条推理路径和进行自我评估,提升了其解决问题的能力。
实验表明,ToT显著提高了语言模型在需要非平凡计划或搜索的新任务(如游戏24、创意写作和微型填字游戏)上的表现。例如,在游戏24中,使用思维链提示的GPT-4只解决了4%的任务,而ToT方法取得了74%的成功率。
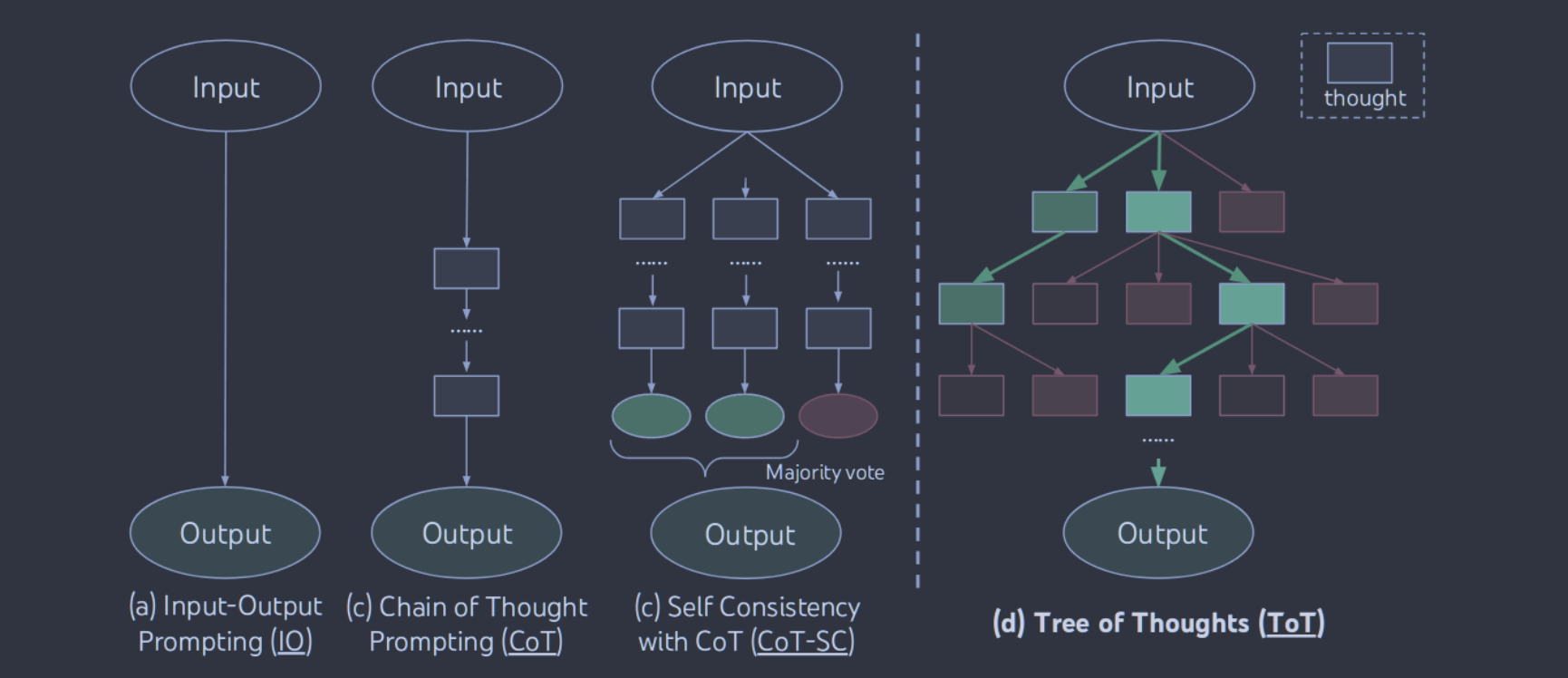
ToT将任何问题框定为树上的搜索,其中每个节点都是一个状态 ,表示到目前为止有输入和思想序列的部分解。
ToT的一个具体实例包括四个问题:如何将中间过程分解为思想步骤;如何从每个状态中产生潜在的思想;如何启发式地评估状态;使用什么搜索算法。
-
思维分解。 CoT在没有显式分解的情况下连贯地采样思维,而ToT利用问题属性来设计和分解中间思维步骤。根据问题的不同,一个思维可以是几个单词(填字游戏)、一行等式( 游戏24),也可以是写作计划的整段(Creative Writing)。一般来说,一个思维应该足够"小",以使LMs能够产生有希望的、多样的样本(例如,生成一本整本书通常太"大"而不连贯),但也应该足够"大",以使LMs能够评估其解决问题的前景(例如,生成一个token通常太"小"而无法评估)。
-
思维发生器 。给定一个树状态 ,用表示参数为θ的预训练LM,用小写字母表示语言序列,即 ,其中每个是一个token,使得。我们考虑了两种策略来生成个候选项用于下一步的思考:
-
(a) 采样 对语言模型的条件概率进行采样,从而生成下一个中间推理步骤: 。
其中 表示第 个可能的中间推理步骤, 表示当前要生成的下一个中间推理步骤。
-
(b) 提出 通过使用“提出提示”的策略(proposal prompting),生成多个中间推理步骤: 。其中表示一组 个可能的中间推理步骤,****表示当前要生成的第 步的 个中间推理步骤。
在24点游戏中使用的是proposal prompting,它的提示词如下:
1 | # 1-shot |
-
状态评估器 利用LM有意地推理作为状态评估器,评估它们在解决问题上的进展,作为搜索算法的启发式(heuristic),以确定哪些状态要继续探索,以何种顺序进行。与思想生成器类似,有两种策略来单独或共同评估状态:
-
( a ) 独立地对每个状态赋值: ,其中 是评估函数, 是当前需要评估的一组状态, 表示在给定状态 的条件下,生成评估值 的概率分布。评估状态,以产生一个标量值 (如1 ~ 10)或一个分类(如确定/可能/不可能)。
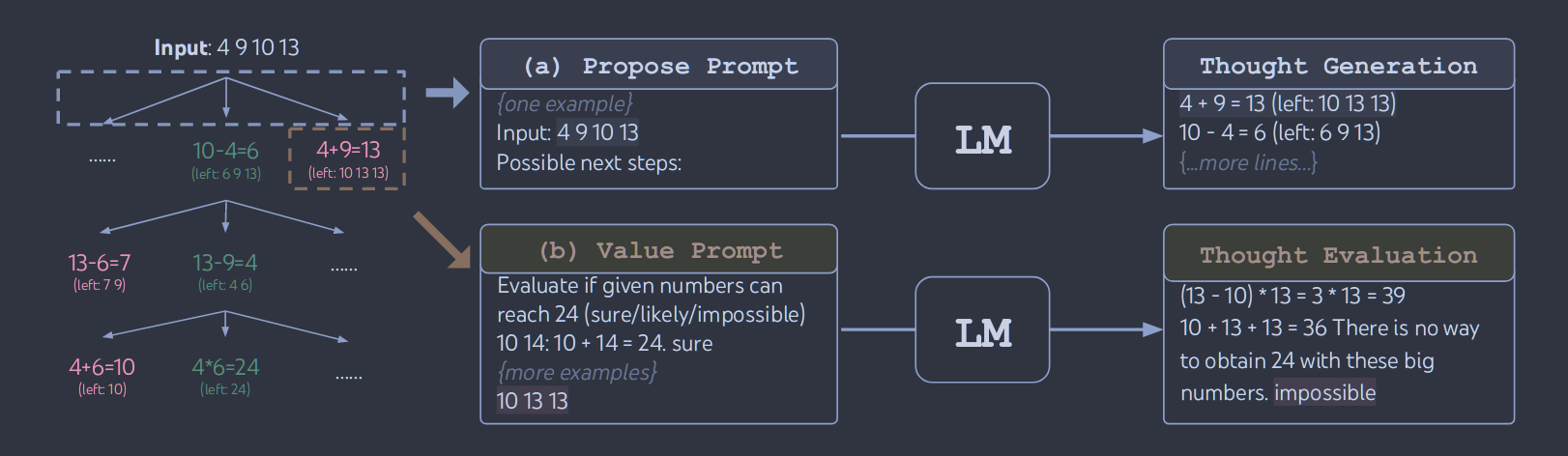
比如24游戏中使用了sure/likely/impossible这种方式
1 | value_prompt = '''Evaluate if given numbers can reach 24 (sure/likely/impossible) |
-
( b )跨状态投票: ,通过投票机制选出一个最优状态 ,然后评估每个状态 。如果某个状态 等于最优状态 ,则该状态的评估值为 1;否则评估值为 0。这种方法用于识别和选择最有希望的状态进行进一步探索。
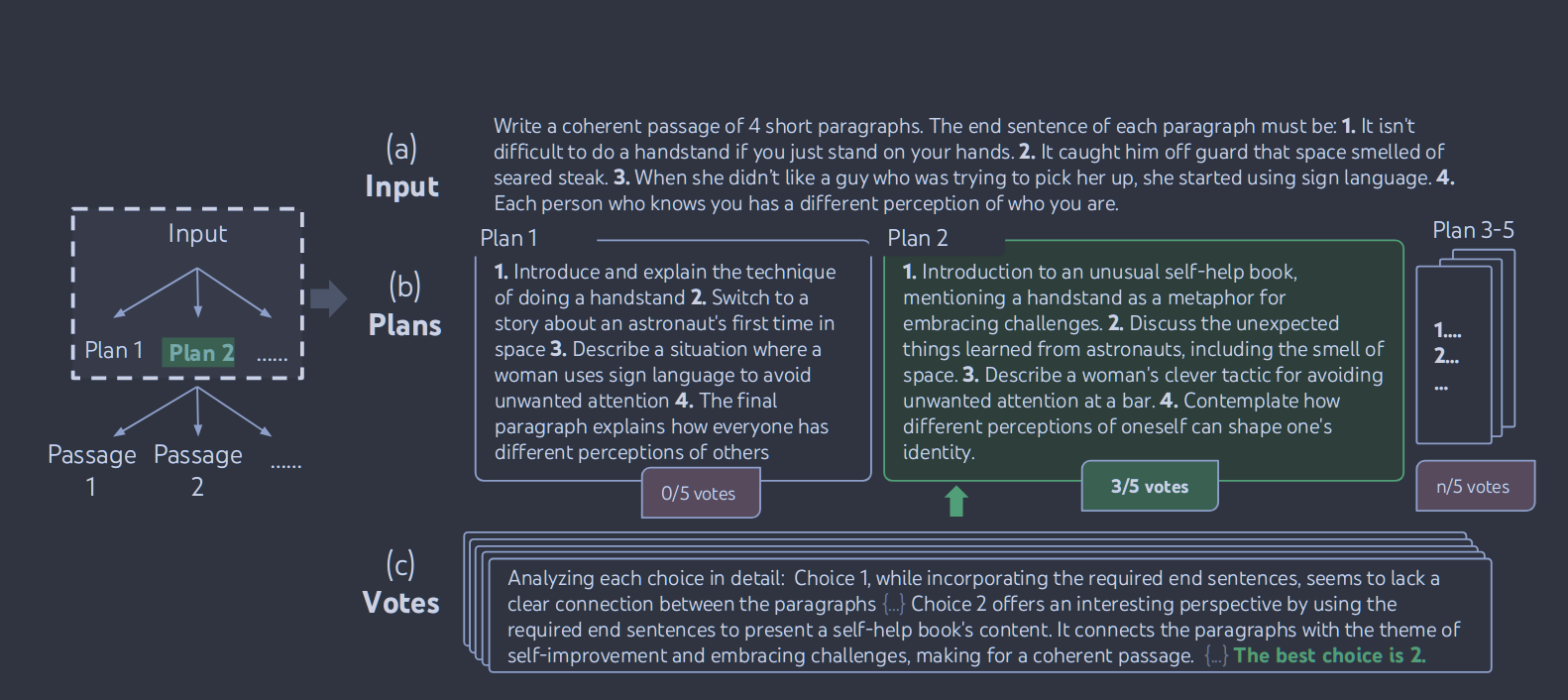
在创造性写作中使用的是跨状态的投票,其提示词如下。
1 | vote_prompt = '''Given an instruction and several choices, decide which choice is most promising. Analyze each choice in detail, then conclude in the last line "The best choice is {s}", where s the integer id of the choice. |
4. 搜索算法。最后,根据树结构采用了两种相对简单的搜索算法:
-
(a) 广度优先搜索(BFS) (算法1)每一步保持一组最有希望的b个状态。这被用于游戏24和创意写作,其中树深度限制为(T≤3),初始思想步骤可以被评估和修剪到一个小的集合( b≤5)。
-
(b) 深度优先搜索(DFS) (算法2 )首先探索最有希望的状态,直到最后的输出达到(t > T),或者状态评估器认为从当前的 为一个值阈值 )不可能解决问题。在后一种情况下,s中的子树被剪枝以进行开发的交易探索。在这两种情况下,DFS都回溯到s的父状态继续探索。
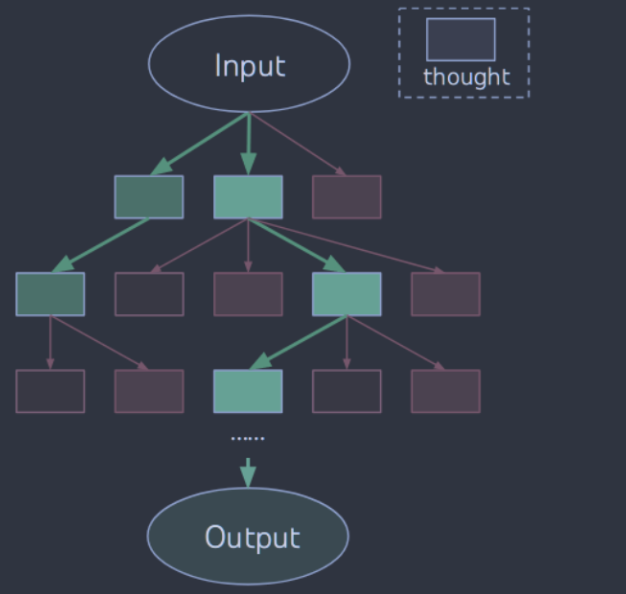
在24点游戏中使用的是bfs,代码片段如下:
1 | def solve(args, task, idx, to_print=True): |
首先根据不同策略生成中间步骤,然后通过value方式进行评估,最后将所有possible和'sure'的结果加入select_new_ys`列表中,作为下一步的输入,进行下一轮评估和选择。



