Parameter-Efficient Transfer Learning for NLP
面向Nlp的参数高效迁移学习
原始论文:《Parameter-Efficient Transfer Learning for NLP》 http://arxiv.org/abs/1902.00751
摘要
微调大型预训练模型是NLP中一种有效的迁移机制。然而,在存在许多下游任务的情况下,微调是参数无效的:每个任务都需要一个全新的模型。作为替代,我们提出了带有适配器模块的传输。适配器模块产生一个紧凑且可扩展的模型;它们每个任务只添加少量可训练的参数,并且可以在不重访以前的任务的情况下添加新的任务。原始网络的参数保持固定,产生高度的参数共享。为了证明适配器的有效性,我们将最近提出的BERT Transformer模型迁移到26个不同的文本分类任务中,包括GLUE基准测试。适配器获得接近最先进的性能,同时每个任务只增加几个参数。在GLUE上,我们实现了0.4%以内的全微调性能,每个任务仅增加3.6%的参数。相比之下,微调训练每个任务100%的参数。
1. 引言
从预训练的模型中迁移在许多NLP任务( Dai & Le , 2015 ; Howard & Ruder , 2018 ;雷德福et al , 2018)上都有很强的性能。BERT是一个在无监督损失的大型文本语料上训练的Transformer网络,在文本分类和抽取式问答( Devlin等, 2018)上取得了先进的性能。在本文中我们处理在线设置,其中任务到达一个流。目标是构建一个在所有任务上都表现良好的系统,但不为每个新任务训练一个全新的模型。
在本文中我们处理在线设置,其中任务到达一个流。目标是构建一个在所有任务上都表现良好的系统,但不为每个新任务训练一个全新的模型。任务之间的高度共享对于诸如云服务之类的应用特别有用,这些应用需要训练模型来解决许多按顺序从客户到达的任务。为此,我们提出了一种迁移学习策略,以产生紧凑且可扩展的下游模型。紧凑型模型是指在每个任务中使用少量的额外参数来解决许多任务的模型。可扩展模型可以通过增量训练来解决新的任务,而不会遗忘先前的任务。我们的方法在不牺牲性能的情况下产生这样的模型。
NLP中最常见的两种迁移学习技术是基于特征的迁移和微调。相反,我们提出了一种基于适配器模块(雷布菲等, 2017)的替代传输方法。基于特征的迁移涉及到预训练的实值嵌入向量。这些嵌入可能是词(米科洛夫等, 2013)、句( Cer et al , 2019),也可能是段落层面的( Le & Mikolov , 2014)。然后将这些嵌入信息传递给自定义的下游模型。微调包括从预训练的网络中复制权重,并在下游任务上进行微调。最近的工作表明,微调往往比基于特征的迁移(霍华德&鲁德, 2018)具有更好的性能。
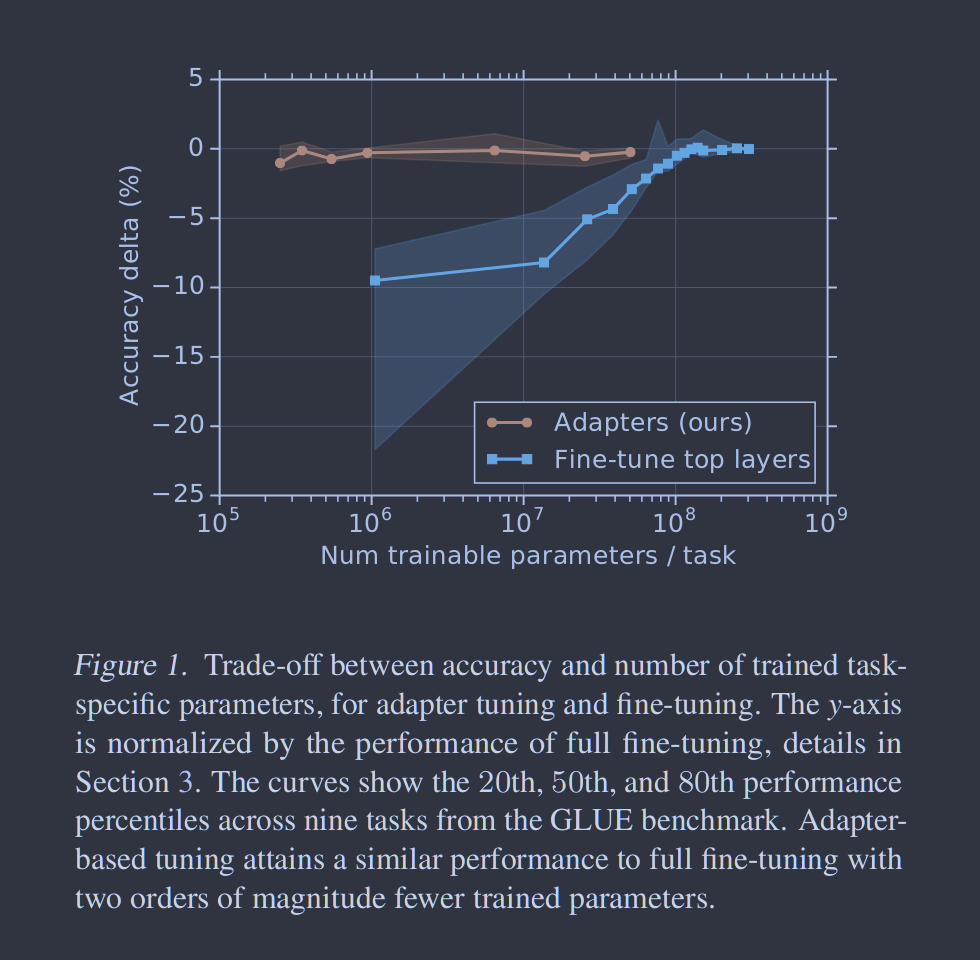
基于特征的迁移和微调都需要为每个任务设置新的权重。如果网络的下层在任务之间共享,则微调更有效。然而,我们提出的适配器调优方法更具有参数效率。图1展示了这种权衡。x轴表示每个任务训练的参数个数;这对应于解决每一个额外任务所需的模型规模的边际增加。基于适配器的调优需要训练少两个数量级的参数进行微调,同时获得相似的性能。
适配器是在预训练网络的层与层之间添加的新模块。基于适配器的调优与基于特征的迁移和微调的方式不同。考虑一个参数为的函数(神经网络): 。基于特征的迁移将 和一个新的函数结合起来,得到 。然后只训练新的Taskspecific参数 。微调包括调整每个新任务的原始参数,以限制紧凑性。对于适配器调优,定义了一个新的函数 ,其中参数 是从预训练中复制过来的。设置初始参数,使新函数与原函数相似: 。在训练过程中,只对 进行调整。对于深度网络,定义 通常需要在原始网络中增加新的层,即 。如果选择 ,则对于许多任务,所得到的模型要求 参数。由于 是固定的,因此模型可以扩展到新的任务而不影响以前的任务。
基于适配器的调节涉及多任务和持续学习。多任务学习也会产生紧凑的模型。然而,多任务学习需要同时访问所有任务,而基于适配器的调优则不需要。持续学习系统旨在从层出不穷的任务中学习。这种范式具有挑战性,因为网络在重新训练( McCloskey& Cohen , 1989 ; French , 1999)后忘记了先前的任务。适配器的不同之处在于任务不交互,共享参数被冻结。这意味着模型使用少量的任务特定参数对先前任务进行完美记忆。
我们在一组大型且多样化的文本分类任务上演示了适配器对NLP进行参数高效调优。关键创新点在于设计了有效的适配器模块及其与基础模型的集成。我们提出了一个简单而有效的瓶颈体系结构。在GLUE基准上,我们的策略几乎匹配了完全微调的BERT的性能,但只使用了3%的任务特定参数,而微调使用了100%的任务特定参数。我们在另外17个公开的文本数据集和SQuAD抽取式问答上观察到类似的结果。总之,基于适配器的调优产生了一个单一的、可扩展的模型,在文本分类中达到了接近最先进的性能。
2. 针对NLP的适配器调优
我们提出了一种在多个下游任务上调优大型文本模型的策略。我们的策略有三个关键特性:(i)它获得了良好的性能;(ii)它允许对任务进行顺序训练,即它不需要同时访问所有的数据集;(iii)它只在每个任务中添加少量的额外参数。这些特性在云服务的背景下特别有用,其中许多模型需要在一系列下游任务上进行训练,因此高度共享是可取的。
为了实现这些特性,我们提出了一个新的瓶颈适配器模块。使用适配器模块进行调优需要在模型中添加少量新参数,这些参数在下游任务(雷布菲等, 2017)上进行训练。在对深度网络进行初始微调时,对网络的顶层进行了修改。这是因为上下游任务的标签空间和损失是不同的。适配器模块执行更一般的架构修改,以便为下游任务重新使用预训练的网络。特别地,适配器调优策略涉及向原始网络中注入新的层。原始网络的权值是不接触的,而新的适配器层是随机初始化的。在标准微调中,新的顶层和原始权重共同训练。相反,在适配器调整中,原始网络的参数被冻结,因此可能被许多任务共享。
适配器模块主要有两个特点:少量的参数和一个拟恒等的初始化。与原有网络的各层相比,适配器模块需要更小。这意味着当增加更多的任务时,模型的总规模增长相对缓慢。为了适应模型的稳定训练,需要一个拟恒等初始化;我们在3.6节中对此进行了实证研究。通过将适配器初始化为拟恒等函数,原始网络在训练开始时不受影响。在训练过程中,适配器可能会被激活,从而改变激活在整个网络中的分布。如果不需要,适配器模块也可能被忽略;在3.6节中,我们观察到一些适配器对网络的影响大于其他适配器。我们还观察到,如果初始化偏离恒等函数太远,模型可能无法训练。
2.1 变压器网络实例化
我们实例化了基于适配器的文本转换器调优。这些模型在许多NLP任务中取得了先进的性能,包括翻译、抽取式问答和文本分类问题( Vaswani et al , 2017 ;Devlin et al , 2018 ; Devlin et al , 2018)。我们考虑Vaswani等( 2017 )提出的标准Transformer结构。
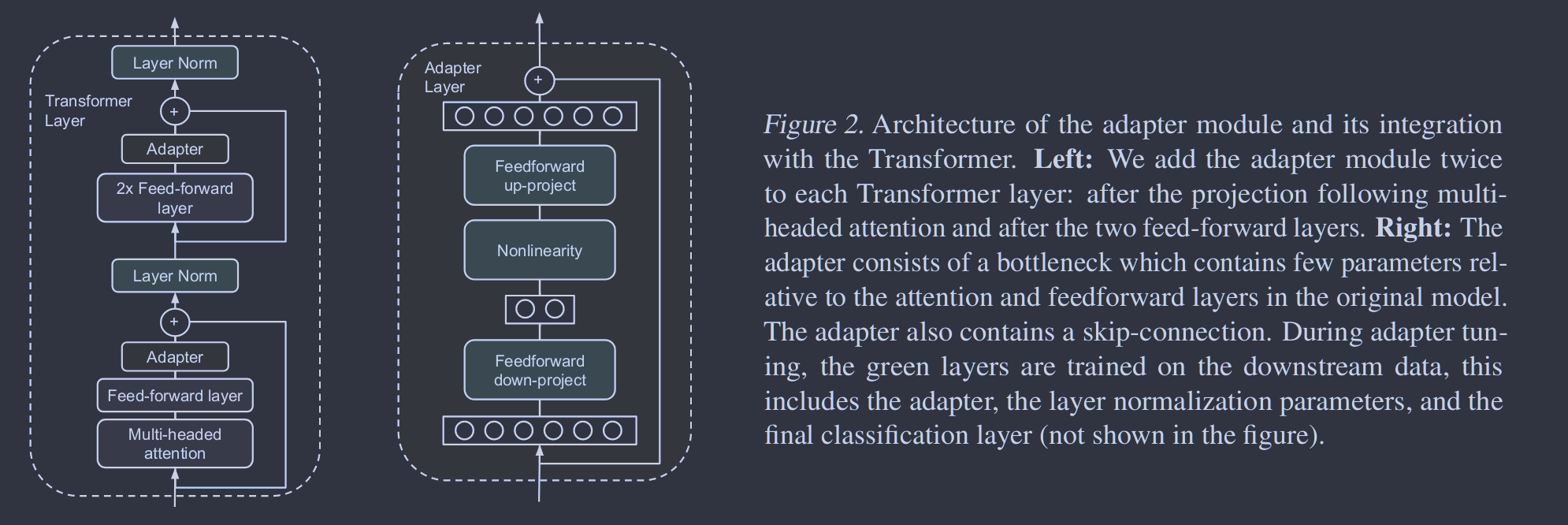
适配器模块提供了许多架构选择。我们提供了一个简单的设计,获得了良好的性能。我们对一些更复杂的设计进行了实验,见3.6节,但我们发现在许多数据集上,以下策略与我们测试的任何其他策略一样。
图2展示了我们的适配器架构,以及它在Transformer上的应用。Transformer的每一层包含两个主要的子层:注意力层和前馈层。这两层后面紧接着一个投影,将特征大小映射回层输入的大小。在每个子层之间应用跳跃连接。每个子层的输出被送入层归一化。我们在每个子层之后插入两个串行适配器。适配器总是直接应用于子层的输出,在投影后回到输入大小,但在加入跳过连接之前回来。然后将适配器的输出直接传入下一层归一化。
为了限制参数的数量,我们提出了瓶颈架构。适配器首先将原始的 维特征投影到一个更小的维度 ,施加一个非线性,然后再投影回 维。每层增加的参数总数,包括偏差,为 。通过设置 ,我们限制了每个任务添加的参数数量;在实际操作中,我们使用了原模型参数的0.5-8%左右。瓶颈维度 提供了一种简单的方法来权衡性能和参数效率。适配器模块本身内部存在跳接。通过跳跃连接,如果投影层的参数初始化为近零,则模块初始化为近似恒等函数。
除了适配器模块中的层外,我们还在每个任务中训练新的层标准化参数。该技术类似于条件批归一化( De Vries et al , 2017)、FiLM (Perez等, 2018)和自调制( Chen et al. , 2019),同样可以实现网络的参数有效自适应;每层只有 个参数。然而,仅训练层归一化参数不足以获得良好的性能,见3.4节。
3. 实验
我们展示出了适配器实现文本任务的参数高效传递。在GLUE基准(Wang et al. , 2018)上,适配器调优在BERT完全微调的0.4%以内,但仅增加了微调训练参数数量的3%。我们在进一步的17个公开分类任务和SQuAD问题回答上证实了这一结果。分析表明,基于适配器的调优自动聚焦于网络的高层。
3.1 实验设置
我们使用公开的、预训练的BERT Transformer网络作为我们的基础模型。为了使用BERT进行分类,我们遵循Devlin et al . ( 2018 )的方法。每个序列中的第一个标记是一个特殊的"分类标记"。我们在这个令牌的嵌入上附加一个线性层来预测类标签。
我们的训练过程也遵循Devlin et al( 2018 )。我们使用Adam ( Kingma & Ba , 2014)进行优化,其学习速率在前10%的步骤中线性增加,然后线性衰减到零。所有运行均在4个批处理大小为32的Google Cloud TPU上训练。对于每个数据集和算法,我们运行一个超参数扫描,根据验证集上的准确率选择最佳模型。对于GLUE任务,我们报告了提交网站提供的测试指标。对于其他分类任务,我们报告了测试集准确率。
我们与目前大型预训练模型迁移的标准--微调--以及BERT成功使用的策略进行了比较。对于N个任务,完全微调需要N×预训练模型的参数个数。我们的目标是达到等同于微调的性能,但总参数较少,理想情况下接近于1×。
3.2 GLUE基准
我们首先在GLUE上进行评估。对于这些数据集,我们从预先训练好的BERTLARGE模型转移而来,该模型包含24层,共330M个参数,详见Devlin et al ( 2018 )。我们执行一个小的超参数扫描来调整适配器:我们扫描{ $3·10^{-5},3·10^{-4},3·10^{-3} $}中的学习率和{ 3,20 }中的历元数。我们使用固定的适配器大小(瓶颈中的单元数量)进行测试,并从{ 8,64,256 }中选择每个任务的最佳大小。适配器大小是我们唯一调整的适配器特定的超参数。最后,由于训练不稳定,我们使用不同的随机种子重新运行5次,在验证集上选择最佳模型。
表1总结了结果。适配器实现了80.0的平均GLUE评分,而完全微调实现了80.4。每个数据集的最佳适配器大小不同。例如,MNLI选择256,而对于最小的数据集,选择RTE,8。始终限制为64,导致平均准确率小幅下降到79.6。为了求解表1中的所有数据集,微调需要BERT参数总数的9倍。相比之下,适配器只需要1.3倍的参数。
3.3 额外的分类任务
为了进一步验证适配器产生紧凑的、性能良好的模型,我们在额外的、公开的文本分类任务上进行测试。该套件包含多样化的任务集:训练样本数量从900到330k不等,类数量从2到157不等,平均文本长度从57到1.9 k个字符不等。所有数据集的统计和参考文献见附录。
对于这些数据集,我们使用了32的批处理大小。数据集具有多样性,因此我们扫描了广泛的学习率范围:{ $ 1·10^{-5},3·10^{-5},1·10^{-4},3·10^^{-3}$ }。由于数据集较多,我们从验证集学习曲线的检验中,手动从集合{ 20,50,100 }中选择训练历元数。我们为微调和适配器都选择了最优值;具体数值见附录。
我们在{ 2,4,8,16,32,64 }中测试适配器的大小。由于部分数据集较小,对整个网络进行微调可能是次优的。因此,我们运行一个额外的基准:变量微调。为此,我们只微调顶层的n层,并冻结其余层。我们扫描n∈{ 1,2,3,5,7,9,11,12 } .在这些实验中,我们使用了12层的BERTBASE模型,因此,当n = 12时,变量微调包含了完全微调。
与GLUE任务不同的是,这类任务没有全面的最先进的数字集。因此,为了确认我们的基于BERT的模型是有竞争力的,我们收集了自己的基准性能。为此,我们在标准网络拓扑上运行大规模超参数搜索。具体来说,我们运行了与Zoph & Le ( 2017 )类似的单任务Neural AutoML算法;Wong等( 2018 )。该算法在前馈和卷积网络的空间上搜索,堆叠在通过TensorFlow Hub公开可用的预训练文本嵌入模块上。来自TensorFlow Hub模块的嵌入可以被冻结或微调。全文的搜索空间在附录中进行了说明。对于每个任务,我们在CPU上运行AutoML一周,使用30台机器。在这段时间里,算法平均每个任务探索超过10k个模型。我们根据验证集准确率为每个任务选择最佳的最终模型。
表2报告了AutoML基准("无BERT基线")、微调、变量微调和适配器微调的结果。AutoML基线表明BERT模型是有竞争力的。这个基线探索了成千上万个模型,但BERT模型的平均表现更好。我们看到了与GLUE类似的结果模式。适配器调整性能接近全微调(落后0.4% )。微调需要17×BERTBASE的参数数量才能解决所有任务。变量微调的表现略好于微调,而训练层数更少。变量微调的最优设置使得每个任务平均训练52%的网络,总共减少为9.9×个参数。然而,适配器提供了一个更紧凑的模型。他们在每个任务中引入1.14%的新参数,导致所有17个任务的1.19 ×参数。
3.4 参数/性能权衡
适配器的大小控制着参数效率,较小的适配器引入较少的参数,以可能的代价换取性能。为了探索这种权衡,我们考虑了不同的适配器尺寸,并与两种基线进行了比较:(i)仅对BERTBASE的前k层进行微调。(ii)仅对层归一化参数进行微调。学习率采用3.2节给出的范围进行调节。
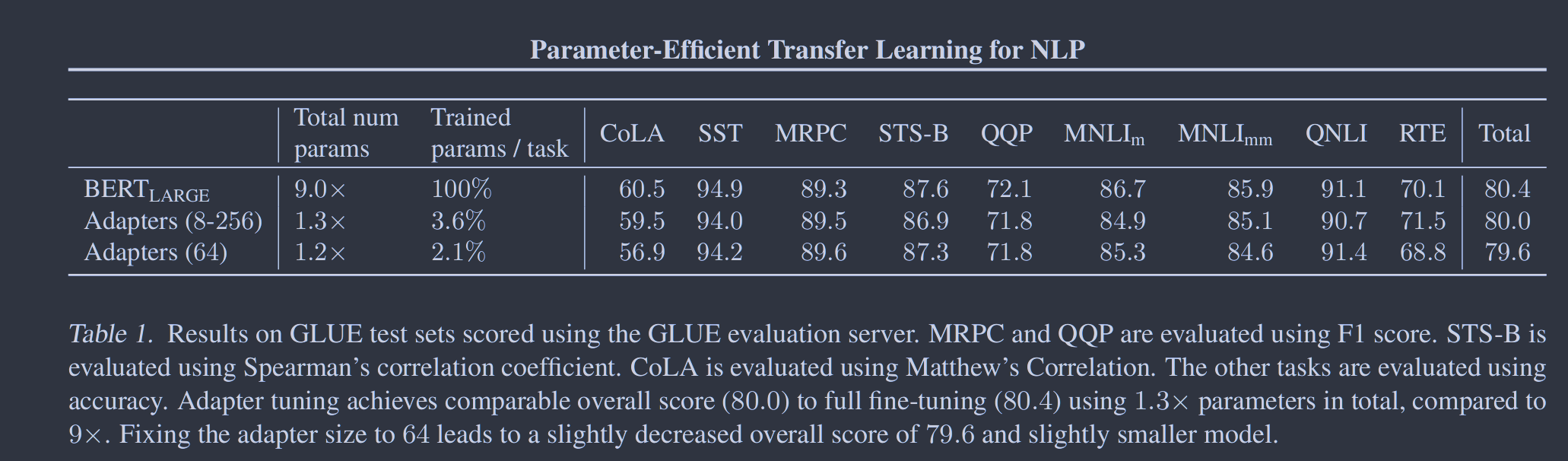
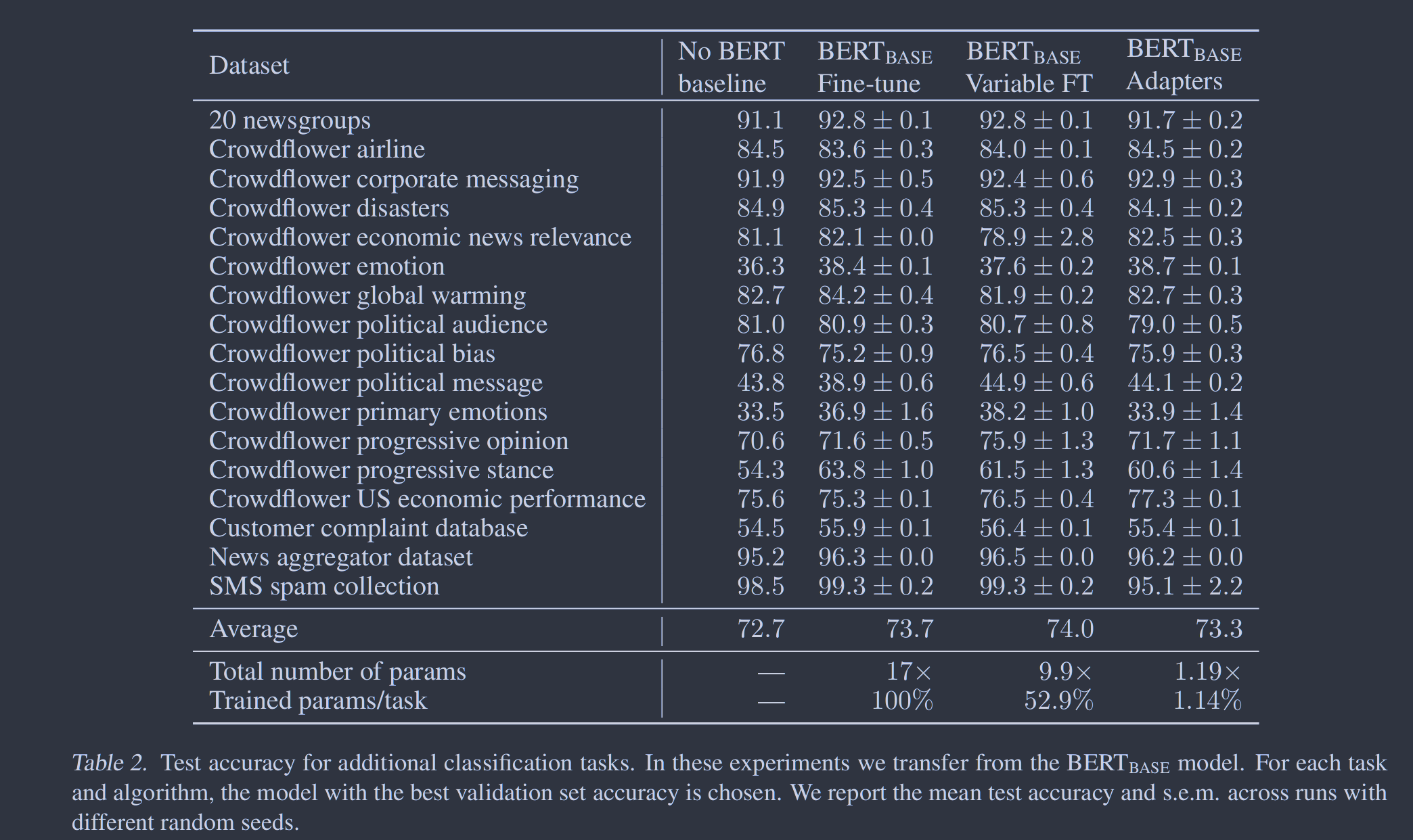
图3显示了每个套件( GLUE和"附加")中所有分类任务的参数/性能权衡。在GLUE上,当微调层数较少时,性能急剧下降。一些额外的任务受益于更少的训练层数,因此微调的性能衰减更少。在这两种情况下,适配器在小于微调两个数量级的尺寸范围内都具有良好的性能。
图4展示了MNLIm和CoLA两个GLUE任务的更多细节。对于所有的k > 2,调整顶层训练更多的任务特定参数。当使用相当数量的任务特定参数进行微调时,与适配器相比,性能大幅下降。例如,仅对顶层进行微调就可以获得约9M的可训练参数和77.8 % ± 0.1 %的MNLIm验证精度。相比之下,尺寸为64的适配器调优产生了大约2M的可训练参数和83.7 % ± 0.1 %的验证精度。作为对比,全微调在MNLIm上达到84.4 % ± 0.02 %。我们在Co LA上也观察到类似的趋势。
作为进一步的比较,我们单独调整层归一化的参数。这些层只包含逐点加法和乘法,因此引入了很少的可训练参数:40k for BERTBASE。然而,该策略表现不佳:在CoLA上性能下降约3.5 %,在MNLI上性能下降约4 %。
总而言之,适配器调优是高参数效率的,并且产生了一个紧凑的模型,具有强大的性能,可与完全微调相媲美。训练尺寸为原始模型的0.5 - 5 %的适配器,性能在BERTLARGE上公开的竞争结果的1 %以内。
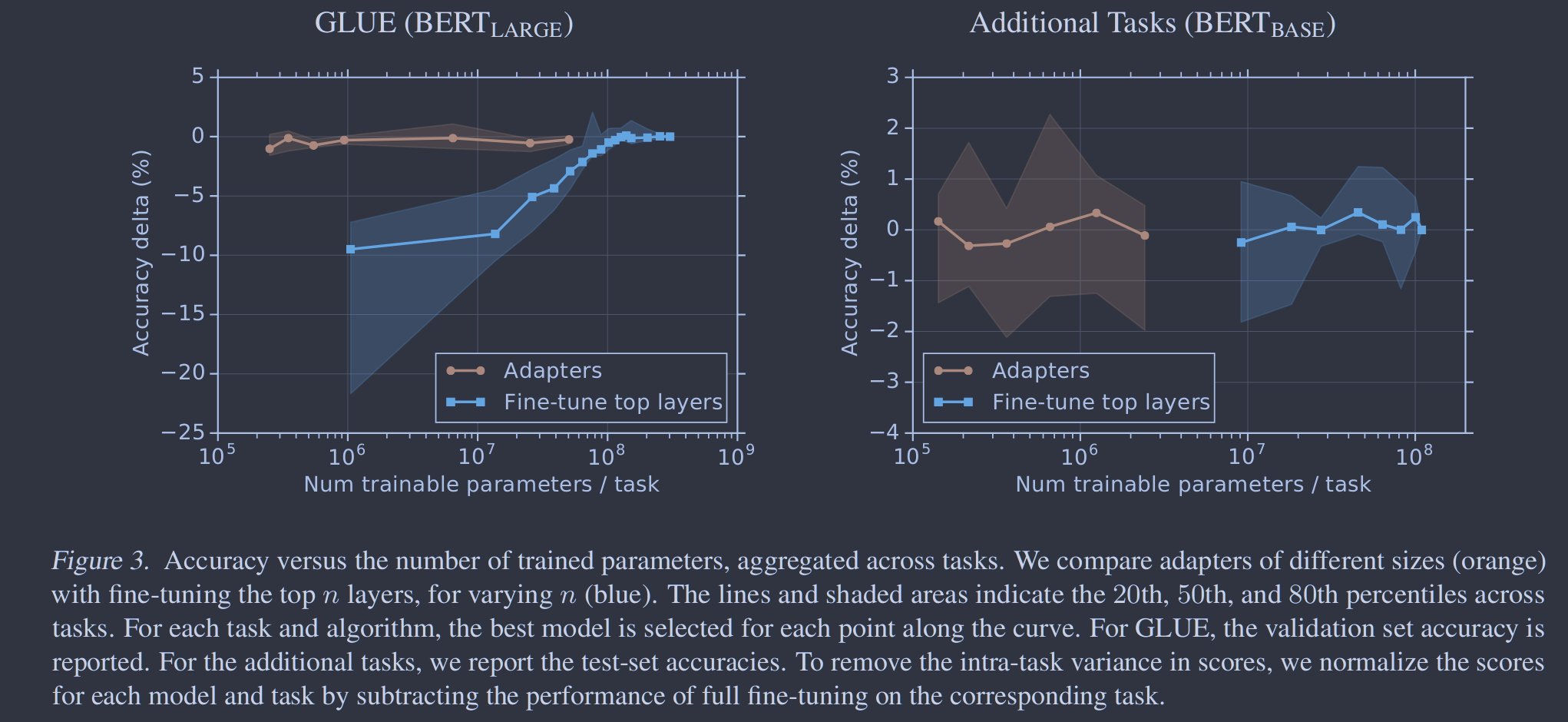 图3. 准确性与训练参数的数量,跨任务聚合。我们比较了不同大小的适配器(橙色)和微调前n层,对于不同的n (蓝色)。线条和阴影区域表示跨任务的第20、50和80百分位数。针对每一个任务和算法,为曲线上的每一个点选择最佳模型。对于GLUE,报告了验证集准确率。对于额外的任务,我们报告了测试集的准确率。为了消除评分中的任务内差异,我们通过减去在相应任务上的完全微调的性能来归一化每个模型和任务的评分。
图3. 准确性与训练参数的数量,跨任务聚合。我们比较了不同大小的适配器(橙色)和微调前n层,对于不同的n (蓝色)。线条和阴影区域表示跨任务的第20、50和80百分位数。针对每一个任务和算法,为曲线上的每一个点选择最佳模型。对于GLUE,报告了验证集准确率。对于额外的任务,我们报告了测试集的准确率。为了消除评分中的任务内差异,我们通过减去在相应任务上的完全微调的性能来归一化每个模型和任务的评分。
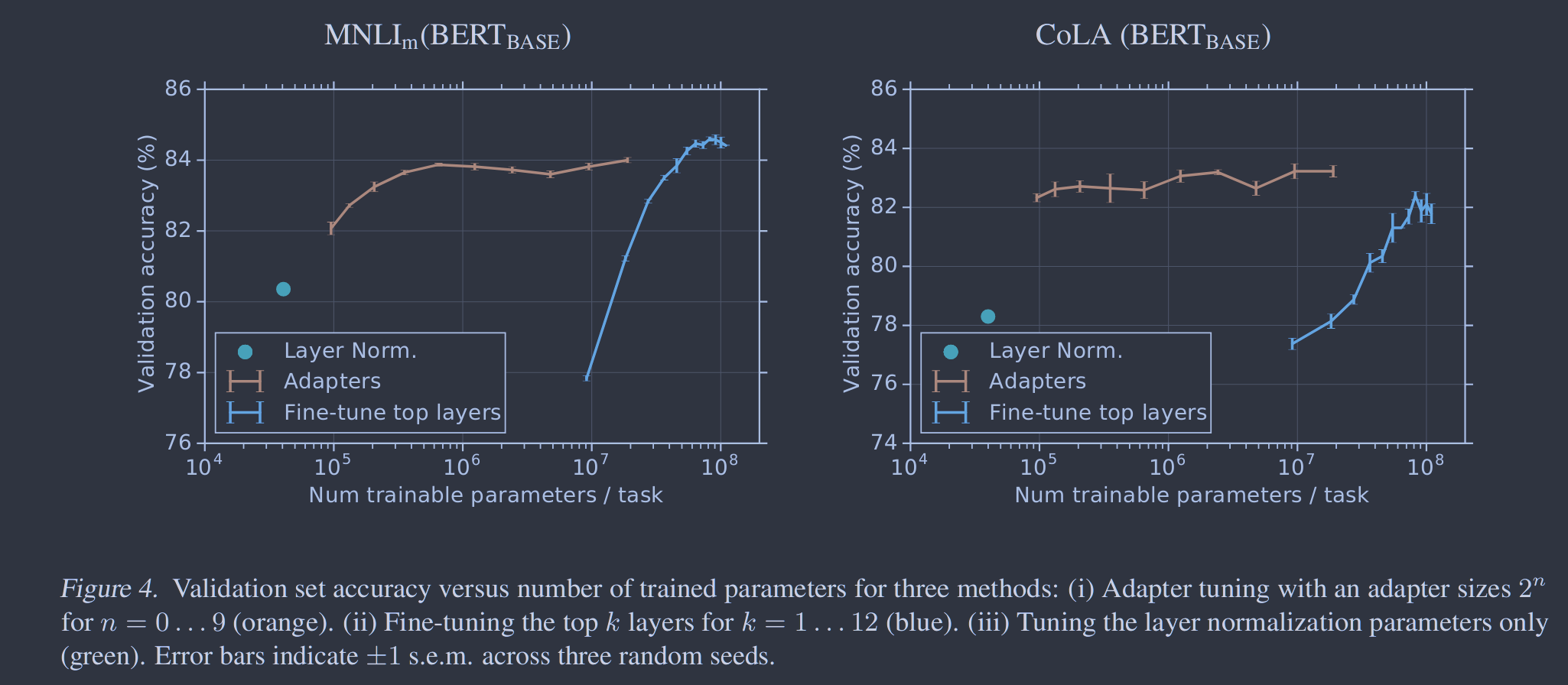
图4. 三种方法的验证集精度与训练参数数量的关系:(i)适配器调优,其中n = 0 ..,适配器大小为2n。9 (橙色)。(ii)对k = 1的前k层进行微调.. 12 (蓝色)。(iii)仅调整图层归一化参数(绿色)。误差条表示三个随机种子的± 1 s.e.m 。
3.5 小队抽取式问答
最后,我们通过在SQuAD v1.1 ( Rajpurkar et al , 2018)上运行,确认适配器工作在分类以外的任务上。给定一个问题和维基百科段落,该任务要求从该段落中选择问题的答案跨度。图5展示了微调和适配器在SQuAD验证集上的参数/性能权衡。对于微调,我们扫描了{ $3·10 ^{-5},5·10^{-5},1·10^{-4} $ }中的训练层数,学习率和{ 2,3,5 }中的迭代次数。对于适配器,我们在{ }中扫描适配器大小,学习率,以及{ 3,10,20 }中的历元个数。在分类方面,适配器获得了与完全微调相当的性能,同时训练了更少的参数。尺寸为64的适配器(2 %的参数)达到了90.4 %的最佳F1,而微调达到了90.7。SQuAD即使在非常小的适配器下也表现良好,大小为2 (0.1%参数)的适配器的F1达到了89.9。
3.6 分析与讨论
我们执行消融来确定哪些适配器是有影响力的。为此,我们删除了一些训练好的适配器,并在验证集上重新评估模型(不需要重新训练)。图6显示了从所有连续层跨中移除适配器时性能的变化。实验在MNLI和CoLA上的适配器大小为64的BERTBASE上进行。
首先,我们观察到移除任何单层的适配器对性能的影响很小。热图对角线上的元素显示了从单层移除适配器的性能,其中最大性能下降为2 %。相比之下,当所有适配器从网络中移除时,性能大幅下降:在MNLI上达到37 %,在预测多数类所获得的CoLA-score上达到69%。这表明虽然每个适配器对整体网络的影响较小,但整体效应较大。
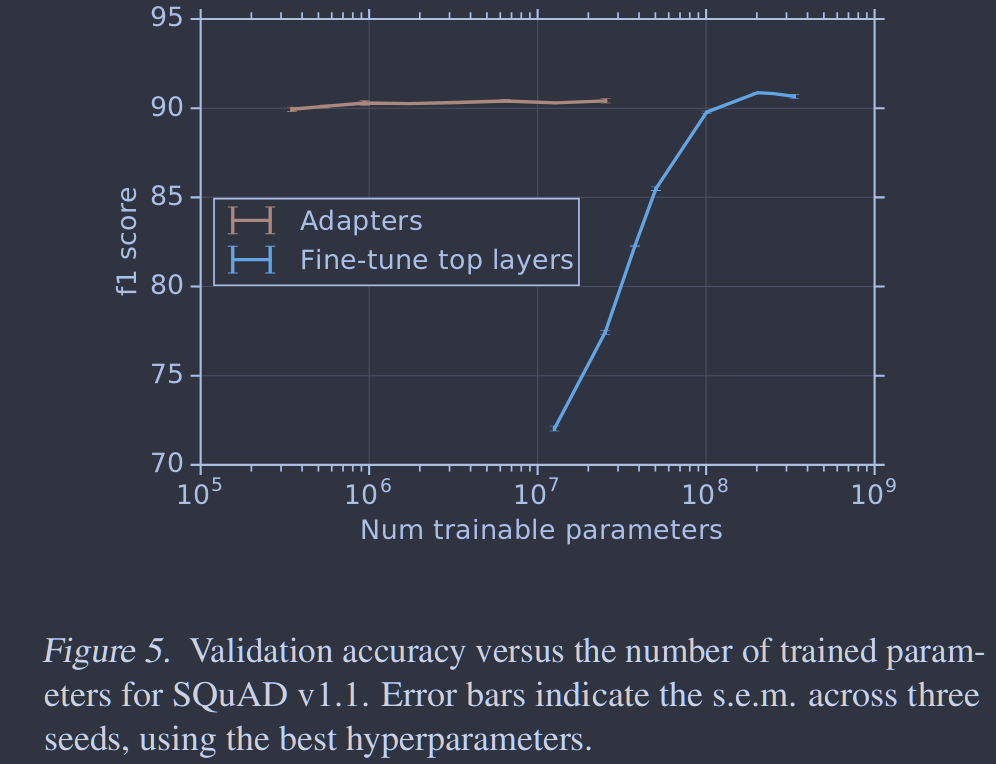 图5. 验证SQuAD v1.1的准确性与训练参数的数量。使用最佳超参数,误差条表示跨越三个种子的s.e.m.
图5. 验证SQuAD v1.1的准确性与训练参数的数量。使用最佳超参数,误差条表示跨越三个种子的s.e.m.
其次,图6表明低层的适配器比高层的适配器具有更小的影响。从MNLI的0-4层移除适配器对性能几乎没有影响。这表明适配器性能良好,因为它们自动优先处理较高的层。事实上,聚焦上层是微调( Howard & Ruder , 2018)的流行策略。一种直觉是,低层提取任务间共享的低层特征,而高层构建不同任务所特有的特征。这与我们的观察有关,对于某些任务,只有顶层的微调优于完全微调,见表2。
接下来,我们研究了适配器模块对神经元数量和初始化规模的鲁棒性。在我们的主要实验中,适配器模块中的权重来自一个标准差为的零均值高斯,截断为两个标准差。为了分析初始化规模对性能的影响,我们在 区间内进行标准差检验。图6总结了结果。我们观察到,在两个数据集上,适配器的性能对以下的标准差都是稳健的。然而,当初始化太大时,性能下降,在CoLA上表现得更明显。
为了考察适配器对神经元数量的鲁棒性,我们重新审视了3.2节的实验数据。我们发现跨适配器大小的模型质量是稳定的,并且在所有任务中使用固定的适配器大小对性能的损害很小。通过选择最优的学习率和迭代次数,我们计算了在八个分类任务中的平均验证精度。对于适配器尺寸为8、64和256,平均验证精度分别为86.2%、85.8 %和85.7 %。图4和图5进一步证实了这一点,它们在几个数量级上都表现出稳定的性能。
最后,我们尝试了一些对适配器架构的扩展,并没有带来性能上的显著提升。为完整起见,我们将其记录在案。我们进行了以下实验:(i)在适配器中添加批/层归一化,(ii)增加每个适配器的层数,(iii)不同的激活函数,如tanh,(iv)只在注意力层内插入适配器,(v)添加与主层平行的适配器,并且可能具有乘法交互。在所有情况下,我们观察到产生的性能与2.1节中提出的瓶颈相似。因此,由于其简单性和强大的性能,我们推荐原始的适配器架构。
4. 相关工作
预训练的文本表示 预训练的文本表示被广泛用于提高NLP任务的性能。这些表示在大型语料库(通常是无监督的)上进行训练,并作为特征输入到下游模型。在深度网络中,这些特征也可能在下游任务上进行微调。基于分布信息训练的布朗簇是预训练表示( Brown et al , 1992)的经典例子。Turian等人( 2010 )的研究表明,预训练的词嵌入比从零开始训练的词嵌入效果更好。自深度学习流行以来,词嵌入得到了广泛的应用,出现了许多训练策略( Mikolov et al . , 2013 ;Pennington et al . , 2014 ;Bojanowski et al . , 2017)。更长的文本、句子和段落的嵌入也被开发出来( Le & Mikolov , 2014 ; Kiros et al , 2015 ;科诺et al , 2017 ; Cer et al , 2019)。
为了在这些表示中编码上下文,从序列模型的内部表示中提取特征,如ELMo (彼得斯等, 2018)中使用的MT系统( McCann等, 2017)和Bi LSTM语言模型。与适配器一样,ELMo利用预训练网络顶层以外的层。然而,这种策略只从内层读取。相反,适配器写入内层,通过整个网络重新配置对特征的处理。
微调 微调整个预训练模型已经成为一种流行的特征替代方法。在NLP中,上游模型通常是神经语言模型( Bengio et al , 2003)。通过对Transformer网络( Vaswani et al , 2017)和隐形语言模型损失( Devlin等, 2018)进行微调,在问答( Rajpurkar等, 2016)和文本分类( Wang et al . , 2018)上取得了最新的研究成果。抛开性能不谈,微调的一个优点是不需要任务特定的模型设计,不像基于表征的迁移。然而,初始精调确实需要为每一个新的任务设置一组新的网络权重。
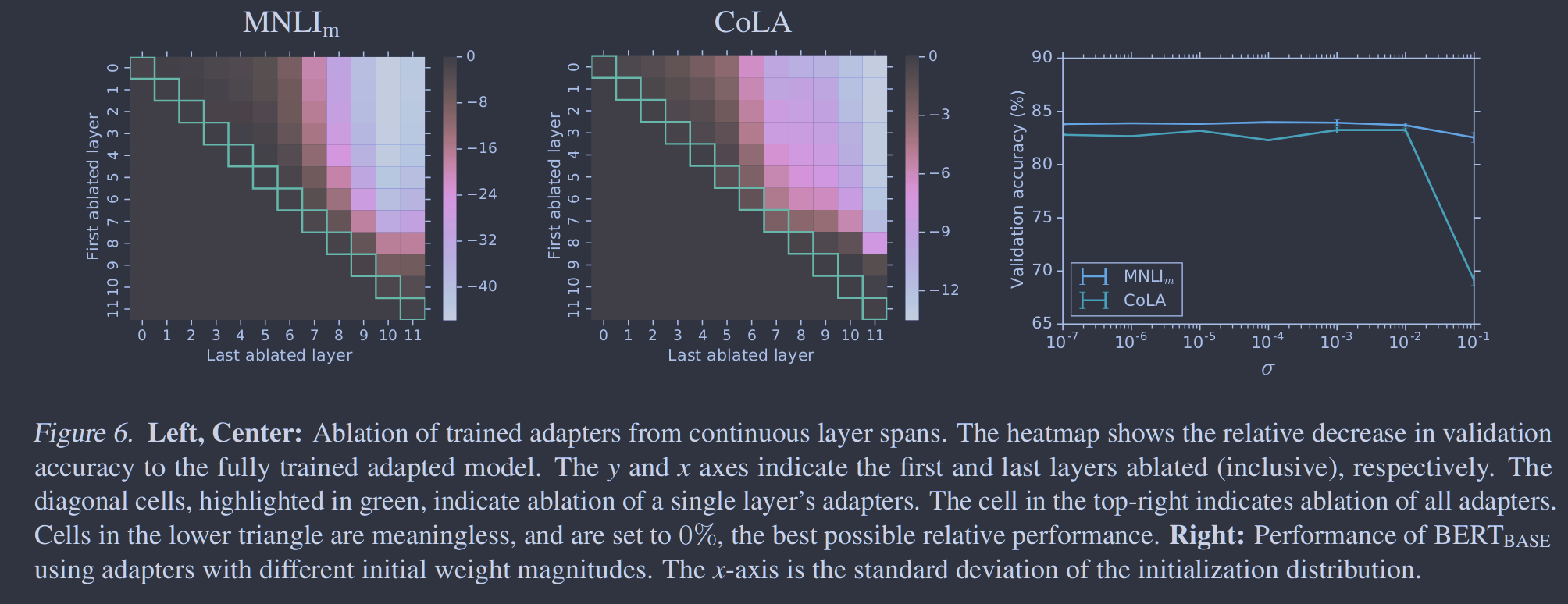 图6. 左,中心:从连续层跨中烧蚀训练好的适配器。热图显示了验证精度相对于充分训练的适应模型的相对下降。y和x轴分别表示第一层和最后一层消融(包括在内)。在绿色中突出的对角线细胞表明单层适配器的消融。右上角的单元格表示所有适配器的消融。下三角形中的细胞是没有意义的,并且设置为0 %,相对性能最好。正确:使用不同初始权重大小的适配器的BERTBASE的性能。x轴是初始化分布的标准差。
图6. 左,中心:从连续层跨中烧蚀训练好的适配器。热图显示了验证精度相对于充分训练的适应模型的相对下降。y和x轴分别表示第一层和最后一层消融(包括在内)。在绿色中突出的对角线细胞表明单层适配器的消融。右上角的单元格表示所有适配器的消融。下三角形中的细胞是没有意义的,并且设置为0 %,相对性能最好。正确:使用不同初始权重大小的适配器的BERTBASE的性能。x轴是初始化分布的标准差。
多任务学习 多任务学习( MTL )是同时对任务进行训练。早期的工作表明,在任务间共享网络参数利用了任务的规律性,产生了改进的性能(Caruana、1997)。作者在网络的低层共享权重,并使用专门的高层。许多NLP系统已经开发了MTL。例如:文本处理系统(词性,组块,命名实体识别等。) (Collobert& Weston , 2008)、多语言模型( Huang et al . , 2013)、语义解析( Peng et al , 2017)、机器翻译(Johnson等, 2017)、问答( Choi et al , 2017)等。MTL产生一个单一的模型来解决所有问题。然而,与我们的适配器不同,MTL需要在训练过程中同时访问任务。
持续学习 作为同时训练、持续学习或终身学习的替代方法,学习旨在从一系列任务( Thrun , 1998)中学习。然而,当重新训练时,深度网络往往会忘记如何执行先前的任务;一个挑战被称为灾难性遗忘(McCloskey & Cohen , 1989 ;French, 1999)。已经提出了一些技术来减轻(Kirkpatrick et al , 2017 ; Zenke et al , 2017)的遗忘,然而,与适配器不同的是,存储器是不完善的。渐进网络通过为每个任务(Rusu 等, 2016)实例化一个新的网络"列"来避免遗忘。然而,参数的数量随着任务数量的增加而线性增长,因为适配器非常小,所以我们的模型具有更好的可扩展性。
视觉中的迁移学习 在构建图像识别模型( Yosinski et al , 2014 ; Huh等, 2016)时,在ImageNet ( Deng et al , 2009)上预训练的微调模型无处不在。该技术在许多视觉任务上获得了最先进的性能,包括分类(Kornblith等, 2018),细粒度分类(Hermans 等, 2017),分割( Long 等 , 2015)和检测( Girshick等, 2014)。在视觉方面,对卷积适配模块(Rebuffi et al , 2017 ; 2018 ; Rosenfeld & Tsotsos , 2018)进行了研究。这些工作通过在ResNet ( He et al , 2016)或VGG Net (Simonyan & Zisserman, 2014)中添加小卷积层来进行多域的增量学习。使用1 × 1卷积限制了适配器的大小,而原始网络通常使用3 × 3。这使得每个任务的整体模型大小增加了11 %。由于无法进一步减小核尺寸,因此必须使用其他权重压缩技术来进一步节省核尺寸。我们的瓶颈适配器可以小得多,并且仍然表现良好。
并行的工作为BERT ( Stickland & Murray , 2019)探索了类似的思路。作者介绍了投影注意力层( Projected Attention Layers,PALs ),它是与我们的适配器具有类似作用的小层。主要区别在于:( 1 ) Stickland & Murray ( 2019 )采用了不同的架构,( 2 )进行多任务训练,在所有GLUE任务上联合微调BERT。新浪塞姆纳尼( 2019 )在SQuAD v2.0 ( Rajpurkar et al , 2018)上对我们的瓶颈Adpaters和PALs进行了实证比较。



