0. Dropout: A Simple Way to Prevent Neural Networks from Overfitting
-
Abstract 摘要部分
:::info
提出问题
:::
Deep neural nets with a large number of parameters are very powerful machine learning systems. However, overfitting is a serious problem in such networks. Large networks are also slow to use, making it difficult to deal with overfitting by combining the predictions of many different large neural nets at test time.
拥有大量参数的深度神经网络是很强大机器学习系统。然而,神经网络的过拟合是一个严峻的问题。大型网络的使用速度也很慢,这使得在测试时结合许多不同的大型神经网络的预测来处理过拟合问题变得困难。
:::info
引出解决方法
:::
Dropout is a technique for addressing this problem.
Dropout 是一种处理这种问题的技术。
:::info
详细介绍该方法
:::
The key idea is to randomly drop units (along with their connections) from the neural network during training. This prevents units from co-adapting too much.
关键思想是通过从训练中的神经网络中随机丢弃(在连接中的)神经元。这种方法阻止了神经元过度的相互适应。
During training, dropout samples from an exponential number of different “thinned” networks. At test time, it is easy to approximate the effect of averaging the predictions of all these thinned networks by simply using a single unthinned network that has smaller weights.
在训练过程中,来自不同指数级的“精简”的网络的样本被丢弃。通过简单使用单个未精简的具有较小权重的网络,就能轻易粗略估计出所有被精简网络的平均精确度的影响。
This significantly reduces overfitting and gives major improvements over other regularization methods. We show that dropout improves the performance of neural networks on supervised learning tasks in vision, speech recognition, document classification and computational biology, obtaining state-of-the-art results on many benchmark data sets.
该方法显著地减少了过拟合并且通过使用其他的正则化方法做出了重大改进。我们证明了dropout确实改善了神经网络在如视觉,语音识别,文件分类和生物计算这些有监督学习任务中的性能提升,并且在许多基准测试数据集中获得了最高水准的结果。
Keywords: neural networks, regularization, model combination, deep learning
关键词:神经网络,正则化,模型融合,深度学习
-
Introduction 导读部分
Deep neural networks contain multiple non-linear hidden layers and this makes them very expressive models that can learn very complicated relationships between their inputs and outputs.
深度神经网络包含了多个非线性隐藏层,这些隐藏层使得模型具有非常好的描述能力,可以从非常复杂的输入输入关系中学习。
With limited training data, however, many of these complicated relationships will be the result of sampling noise, so they will exist in the training set but not in real test data even if it is drawn from the same distribution.
然而在受限的训练集中,许多这种复杂的关系是样本噪声的结果,因此即使是从相同分布中得到的模型,这也结果会存在于训练集中而不在实际的测试数据中。
This leads to overfitting and many methods have been developed for reducing it. These include stopping the training as soon as performance on a validation set starts to get worse, introducing weight penalties of various kinds such as L1 and L2 regularization and soft weight sharing (Nowlan and Hinton, 1992).
这就导致了过拟合,许多方法被开发出来用来降低过拟合。其中包括只要模型在验证集上的性能开始变差就立即结束训练,引入多种权重惩罚,如L1和L2正则化和软权重共享(Nowlan and Hinton, 1992)。
With unlimited computation, the best way to “regularize” a fixed-sized model is to average the predictions of all possible settings of the parameters, weighting each setting by its posterior probability given the training data. This can sometimes be approximated quite well for simple or small models (Xiong et al., 2011; Salakhutdinov and Mnih, 2008), but we would like to approach the performance of the Bayesian gold standard using considerably less computation. We propose to do this by approximating an equally weighted geometric mean of the predictions of an exponential number of learned models that share parameters.
在算力没有限制的情况下,对固定大小的模型的进行正则化的最佳方法是对参数的所有可能设置的预测进行平均,通过其训练数据的后验概率对每个设置进行加权。这种方法在简单和小模型的情况下可以估计的相当准确,但是我们想通过相当低的算例来实现贝叶斯黄金法则的性能。我们建议通对一个指数级数量共享参数的学习过的模型的准确率的等权重几何平均值进行近似来做到这一点。
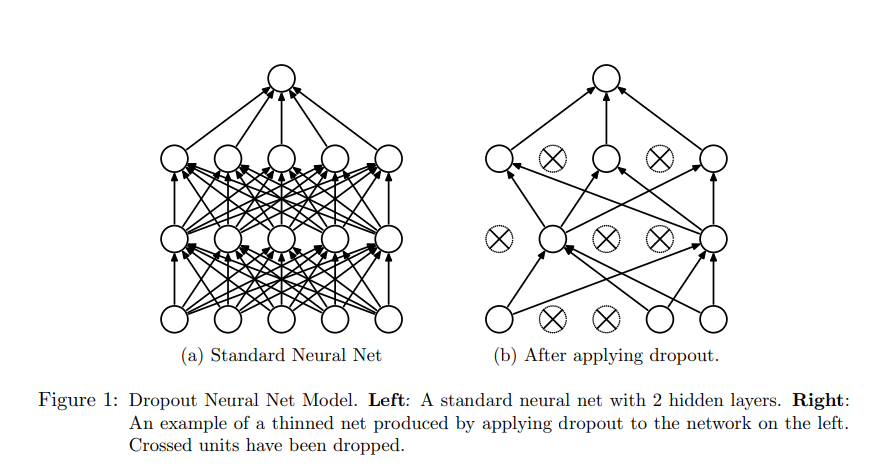
图1: dropout神经网络模型。左侧:有两层隐藏层的标准神经网络。右侧:在左侧网络上应用了dropout处理后的精简网络举例。叉号的神经元被丢弃了。
Model combination nearly always improves the performance of machine learning methods. With large neural networks, however, the obvious idea of averaging the outputs of many separately trained nets is prohibitively expensive. Combining several models is most helpful when the individual models are different from each other and in order to make neural net models different, they should either have different architectures or be trained on different data. Training many different architectures is hard because finding optimal hyperparameters for each architecture is a daunting task and training each large network requires a lot of computation. Moreover, large networks normally require large amounts of training data and there may not be enough data available to train different networks on different subsets of the data. Even if one was able to train many different large networks, using them all at test time is infeasible in applications where it is important to respond quickly.
模型组合几乎一直都在提升机器学习方法的性能。然而对于大的神经网络来说,从许多分别训练的网络的输出中取出均值这种显而易见的想法是极其昂贵的。当独特的模型于其他模型不同时,为了使神经网络模型是独特的,组合多个模型是最有用的,它们也需要有不同的架构或者用不同的数据上训练。训练许多不同的架构是困难的,因为为每个架构寻找最优的超参数是一份令人生畏的任务,并且训练每个大网络需要大量的算力。除此之外,大的网络通常需要大量的训练数据,而可能没有足够多的可用数据使在不同的数据子集上训练不同的网络。即使有人能够训练许多不同大网络,在迅速响应是关键的应用测试时使用这些网络也是不切实际的。
Dropout is a technique that addresses both these issues. It prevents overfitting and provides a way of approximately combining exponentially many different neural network architectures efficiently. The term “dropout” refers to dropping out units (hidden and visible) in a neural network. By dropping a unit out, we mean temporarily removing it from the network, along with all its incoming and outgoing connections, as shown in Figure 1. The choice of which units to drop is random. In the simplest case, each unit is retained with a fixed probability p independent of other units, where p can be chosen using a validation set or can simply be set at 0.5, which seems to be close to optimal for a wide range of networks and tasks. For the input units, however, the optimal probability of retention is usually closer to 1 than to 0.5.
dropout是一种处理这些问题的技术。它抑制了过拟合并且提供了一种方法去近似地将许多不同的神经网络结构以指数形式有效地组合在一起。"dropout"这一术语来源于在神经网络中丢弃(隐藏的和可见的)神经元。如图一所示,通过丢弃一个神经元,我们打算暂时的将它连同它的所有输入输出连接移除出当前网络。对于要丢弃神经元的选择是随机的。在最简单的情况下,每个神经元都以独立于其他神经元的固定概率p保留,其中p可以是使用验证集挑选,也可以是简单地设置为0.5,这对于大范围网络和任务几乎是最优解。然而,对于输入神经元,最佳的保留概率通常接近1而不是0.5 。
Applying dropout to a neural network amounts to sampling a “thinned” network from it. The thinned network consists of all the units that survived dropout (Figure 1b). A neural net with n units, can be seen as a collection of 2n possible thinned neural networks. These networks all share weights so that the total number of parameters is still $O(n^2) $, or less. For each presentation of each training case, a new thinned network is sampled and trained. So training a neural network with dropout can be seen as training a collection of 2n thinned networks with extensive weight sharing, where each thinned network gets trained very rarely, if at all.
在一个神经网络中应用droupout相当于是从一个神经网络中采样一个"稀释"网络 。这个稀释网络包含所有存活的dropout神经元(图1b) 。一个有n个神经元的神经网络可以被视为2n个可能的稀释神经网络。这些网络全都分享权重,因此所有的参数数量级仍然是$O(n^2) $或更低。对于每个训练案例的每种标识,一个新的稀疏网络被采样和训练。因此训练一个带有dropout的神经网络可以被视作是训练一个有2n个带有广泛权重共享的稀疏网络集合,其中的每个稀疏网络得到了非常少的训练。
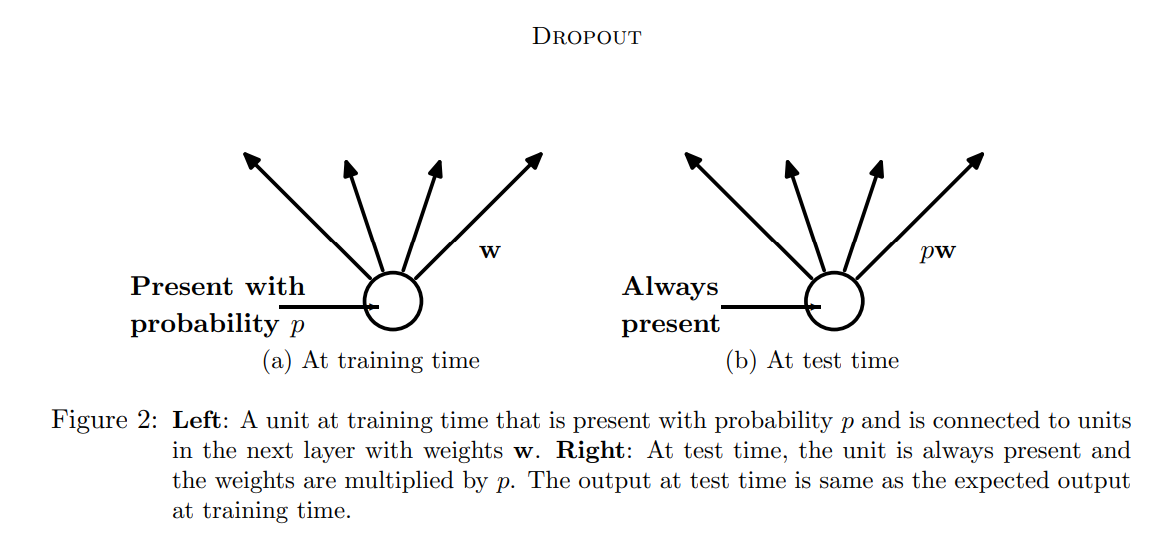
图2:左侧:一个训练时的神经元,该神经元以概率p存在,并与权重为w的下一层单元相连接。右侧:在测试时,这个神经元一直存在,并且权重乘以p。在测试时的输出与在训练时的预期输出相符合。
At test time, it is not feasible to explicitly average the predictions from exponentially many thinned models. However, a very simple approximate averaging method works well in practice. The idea is to use a single neural net at test time without dropout. The weights of this network are scaled-down versions of the trained weights. If a unit is retained with probability p during training, the outgoing weights of that unit are multiplied by p at test time as shown in Figure 2. This ensures that for any hidden unit the expected output (under the distribution used to drop units at training time) is the same as the actual output at test time. By doing this scaling, 2n networks with shared weights can be combined into a single neural network to be used at test time. We found that training a network with dropout and using this approximate averaging method at test time leads to significantly lower generalization error on a wide variety of classification problems compared to training with other regularization methods.
在测试时,从指数级系数模型中得到确切平均准确率是不切实际的。然而,一个非常简单的近似平均方法在实际工作中表现的很好。这个方法是在测试时用没有dropout的单个神经网络。这个网络的权重是训练过权重的成比例缩小的版本。如果一个神经元在训练过程中保留了概率p,那么在测试时神经元的输出权重会是p的倍数,如图2所示。这个保证了对于任意隐藏的神经元,(在训练时用于丢弃神经元的分布情况下)期望输出与实际测试时的输出是一致的。通过这种缩放,2n个带有权值共享的神经网络能够在测试时被拼合进单个神经网络。我们发现,在广类型的分类问题上,相较于其他正则化方法,训练一个带有dropout的网络并在测试时使用这种近似平均的方法,会使得泛化误差显著地降低。
The idea of dropout is not limited to feed-forward neural nets. It can be more generally applied to graphical models such as Boltzmann Machines. In this paper, we introduce the dropout Restricted Boltzmann Machine model and compare it to standard Restricted Boltzmann Machines (RBM). Our experiments show that dropout RBMs are better than standard RBMs in certain respects.
这个dropout方法不仅局限于前馈神经网络,它也能被更广泛的应用于如玻尔兹曼机这样的图形模型。在这篇文章中,我们介绍了dropout约束的玻尔兹曼机模型并且将其于标准的玻尔兹曼机(RBM)加以比较。我们的实验表明dropout RBMs在某些方面优于标准RBMs。
This paper is structured as follows. Section 2 describes the motivation for this idea. Section 3 describes relevant previous work. Section 4 formally describes the dropout model. Section 5 gives an algorithm for training dropout networks. In Section 6, we present our experimental results where we apply dropout to problems in different domains and compare it with other forms of regularization and model combination. Section 7 analyzes the effect of dropout on different properties of a neural network and describes how dropout interacts with the network’s hyperparameters. Section 8 describes the Dropout RBM model. In Section 9 we explore the idea of marginalizing dropout. In Appendix A we present a practical guide for training dropout nets. This includes a detailed analysis of the practical considerations involved in choosing hyperparameters when training dropout networks.
这篇文章结构如下:第二部分介绍了这种思路的动机,第三部分介绍了先前的相关工作,第四部分正式介绍dropout模型,第五部分给出了一个用来训练dropout模型的算法,第六部分,我们展示了我们的实验结果,在实验中我们将dropout应用到不同领域的问题,并与其他形式的正则化和模型组合方法对比。第七部分分析了dropou对不同特性神经网络的影响,并描述了dropout如何与神经网络的超参数相互作用。第八部分介绍了dropout RBM模型。在第九部分,我们探索了边缘化dropout的思路。在附录中,我们展示了一个训练dropout模型的实现手册,它包含了在训练dropout网络时包含选择超参数的实际情况的详细分析报告。
-
Motivation 动机部分
A motivation for dropout comes from a theory of the role of sex in evolution (Livnat et al., 2010). Sexual reproduction involves taking half the genes of one parent and half of the other, adding a very small amount of random mutation, and combining them to produce an offspring. The asexual alternative is to create an offspring with a slightly mutated copy of the parent’s genes. It seems plausible that asexual reproduction should be a better way to optimize individual fitness because a good set of genes that have come to work well together can be passed on directly to the offspring. On the other hand, sexual reproduction is likely to break up these co adapted sets of genes, especially if these sets are large and, intuitively, this should decrease the fitness of organisms that have already evolved complicated coadaptations. However, sexual reproduction is the way most advanced organisms evolved.
一个dropout的动机是来源于一个关于性别在进化中所起作用的理论(Livnat et al., 2010)。有性生殖包含了双亲各一半的基因,加上一个非常小数量的随机突变,这些结合起来产生了后代。而无性生殖产生后代的替代方案是创造一个与双亲基因有微小差异的拷贝。无性生产似乎是可靠的,它应该是一种更好的优化个体适应性的方式,因为一组表现优异的基因能够直接地传递给后代。在另一方面,有性生殖似乎在拆散这些相互适应的基因组,特别是当这些基因组在直觉上看来是庞大的,这应该会降低已经进化出复杂相互适应的生物体的适应性。然而,有性生殖却是最高等的生物进化方式。
One possible explanation for the superiority of sexual reproduction is that, over the long term, the criterion for natural selection may not be individual fitness but rather mix-ability of genes.
一个可能的有性生殖优越性的解释是这样的:长期以来,自然选择的标准也许并不是个体适应性而是基因的混合能力。
The ability of a set of genes to be able to work well with another random set of genes makes them more robust. Since a gene cannot rely on a large set of partners to be present at all times, it must learn to do something useful on its own or in collaboration with a small number of other genes.
这种一组基因能够在其他随机基因组协同工作良好的能力使得他们更加的健壮。因为一个基因不能在任何时候都依赖于一个存在的大的伴侣组,它必须在他自己或与一个小数量的其他基因协作的协作中学习做一些有用的事情。
According to this theory, the role of sexual reproduction is not just to allow useful new genes to spread throughout the population, but also to facilitate this process by reducing complex co-adaptations that would reduce the chance of a new gene improving the fitness of an individual.
根据这个理论,有性生殖的作用不仅是允许有益的新基因通过族群传播,也通过降低共同适应的复杂度来促进这个过程,这种共同适应会降低新基因提升个体适应性的可能性。
Similarly, each hidden unit in a neural network trained with dropout must learn to work with a randomly chosen sample of other units. This should make each hidden unit more robust and drive it towards creating useful features on its own without relying on other hidden units to correct its mistakes.
同样的,在神经网络中每个通过dropout训练的的隐藏神经元必须学习与随机选取的神经元样本作用。这应该使得每个隐藏神经元更健壮并且向前驱使它在不依赖其他隐藏神经元来纠正自己错误的情况下,在自己身上创造更有用的特性。
However, the hidden units within a layer will still learn to do different things from each other. One might imagine that the net would become robust against dropout by making many copies of each hidden unit, but this is a poor solution for exactly the same reason as replica codes are a poor way to deal with a noisy channel.
然而,在一个隐藏层的神经元仍然会从其他的神经元中学到不同的东西。一种假设是,通过对每个隐藏神经元进行多次复制,网络会变得健壮以抗拒被dropout,但是这是一种糟糕的解决方案,就像用复制代码去处理噪声通道的原因一样。
A closely related, but slightly different motivation for dropout comes from thinking about successful conspiracies. Ten conspiracies each involving five people is probably a better way to create havoc than one big conspiracy that requires fifty people to all play their parts correctly.
一个dropout被提出的密切相关但又稍微不同的动机是关于成功的合谋。五个人一组的十个合谋,比一个需要五十个人参与并且各司其职的大的合谋,在制造混乱场面来说,似乎是一种更好的方案。
If conditions do not change and there is plenty of time for rehearsal, a big conspiracy can work well, but with non-stationary conditions, the smaller the conspiracy the greater its chance of still working.
如果情况不发生改变并且有大量的预演时间,一个大的合谋可能工作的很好,但是在一个不稳定的环境中,合谋越小,它仍然工作的概率就越大。
Complex co-adaptations can be trained to work well on a training set, but on novel test data they are far more likely to fail than multiple simpler co-adaptations that achieve the same thing.
复杂的相互适应在测试集上能够被训练的相当出色,但是对于新的测试数据,它们可能远不及达到同样效果的多个简单的相互适应。
-
Related Work 相关工作
Dropout can be interpreted as a way of regularizing a neural network by adding noise to its hidden units.
Dropout 可以被理解为是一种在隐藏神经元中增加噪声的神经网络正则化方式。
The idea of adding noise to the states of units has previously been used in the context of Denoising Autoencoders (DAEs) by Vincent et al. (2008, 2010) where noise is added to the input units of an autoencoder and the network is trained to reconstruct the noise-free input.
向神经元的状态中增加噪声的想法已经显而易见地被Vicent等人用在了降噪自编码器(DAEs)中(2008,2010),他们在一个自编码器的输入神经元中加入噪声并训练该网络重构为无噪声输入。
Our work extends this idea by showing that dropout can be effectively applied in the hidden layers as well and that it can be interpreted as a form of model averaging.
我们的工作通过展现dropout能够同样地被有效应用于隐藏层拓展了这种思路,这种思路可以被解释成一种模型均值化的形式。
We also show that adding noise is not only useful for unsupervised feature learning but can also be extended to supervised learning problems.
我们也知道,添加噪声并非是无监督特征学习的唯一有效方式,但是确实也扩展了无监督学习的问题研究。
In fact, our method can be applied to other neuron-based architectures, for example, Boltzmann Machines. While 5% noise typically works best for DAEs, we found that our weight scaling procedure applied at test time enables us to use much higher noise levels.
实际上,我们的方法能被用到其他的基于神经元的架构,比如,玻尔兹曼机。通常对于DAEs有5%的噪声最合适,我们发现我们在测试时应用的权重缩放过程确保我们能使用更多的噪声水平。
Dropping out 20% of the input units and 50% of the hidden units was often found to be optimal.
我们发现,通常丢弃20%的输入神经元和50%的隐藏神经元是最优的。
Since dropout can be seen as a stochastic regularization technique, it is natural to consider its deterministic counterpart which is obtained by marginalizing out the noise.
因为dropout能被视作是一中随机正则化技术,很自然地考虑它通过边缘化噪声得到的确定性对应物。
In this paper, we show that, in simple cases, dropout can be analytically marginalized out to obtain deterministic regularization methods.
在本文,我们证明,在简单情况下,dropout能够被分析边缘化,从而得到确切的正则化方法。
Recently, van der Maaten et al. (2013) also explored deterministic regularizers corresponding to different exponential-family noise distributions, including dropout (which they refer to as “blankout noise”). However, they apply noise to the inputs and only explore models with no hidden layers.
近来,van der Maaten等人(2013)也探索了确定性正则化相当于不同的指数分布族噪声分布,其中包含dropout(他们提到的是熄灭噪声)。然而,他们把噪声应用到了输入并且只研究了没有隐藏层的模型。
Wang and Manning (2013) proposed a method for speeding up dropout by marginalizing dropout noise. Chen et al. (2012) explored marginalization in the context of denoising autoencoders.
Wang和Mannig(2013)提出了一个方法,通过边缘化dropout噪声来加速。Chen等人(2012)研究了降噪自编码器上下文中的边缘化。
In dropout, we minimize the loss function stochastically under a noise distribution. This can be seen as minimizing an expected loss function.
在dropout中,我们通过一个噪声分布随机最小化了函数损失。dropout可以看作是一个最小化期望损失函数。
Previous work of Globerson and Roweis (2006); Dekel et al. (2010) explored an alternate setting where the loss is minimized when an adversary gets to pick which units to drop.
Globerson和Roweis(2006),Dekel(2010)等人的工作探索了一种替代设置,这种设置使得一个对抗体可以选择哪些神经元被丢弃以获得最小的损失。
Here, instead of a noise distribution, the maximum number of units that can be dropped is fixed. However, this work also does not explore models with hidden units.
在文中,与一种噪声分布不同,能被丢弃的最大神经元的数量时被固定的。然而,这个工作并没有探索包含隐藏神经元的模型。
-
Model Description 模型描述
This section describes the dropout neural network model. Consider a neural network with L hidden layers. Let l ∈ {1, . . . , L} index the hidden layers of the network. Let z (l) denote the vector of inputs into layer l, y (l) denote the vector of outputs from layer l (y (0) = x is the input). W(l) and b (l) are the weights and biases at layer l. The feed-forward operation of a standard neural network (Figure 3a) can be described as (for l ∈ {0, . . . , L − 1} and any hidden unit i)
该部分描述了dropout神经网络模型。考虑一个具有L个隐藏层的神经网络,令 $l∈{1,...,L} $ 建立网络中隐藏层的序列号,使 表示第层的输入向量, 表示第 层的输出向量(输入是) 。 和 分别是第 层的权重和偏置值。这个标准神经网络(图3a)的前馈运算能被描述为(对 且对于任意隐藏神经元 )
where is any activation function, for example, .
With dropout, the feed-forward operation becomes (Figure 3b)
其中f是任意激活函数,例如 。带上dropout,这个前馈操作就成了(图3).
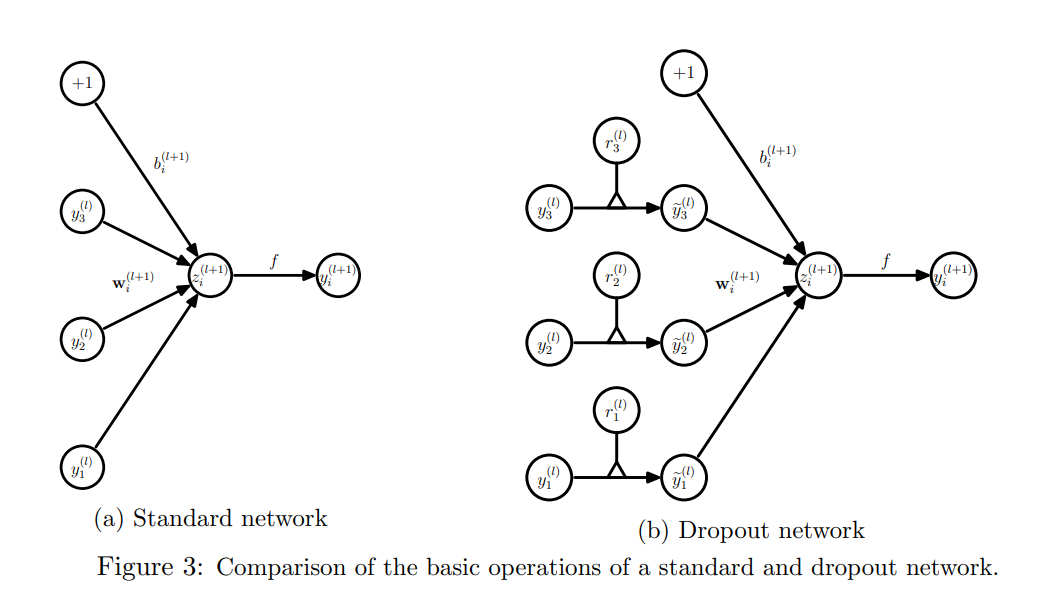
图3:标准网络与drop网络的基本运算对比
Here ∗ denotes an element-wise product. For any layer , is a vector of independent Bernoulli random variables each of which has probability of being . This vector is sampled and multiplied element-wise with the outputs of that layer, , to create the thinned outputs . The thinned outputs are then used as input to the next layer. This process is applied at each layer. This amounts to sampling a sub-network from a larger network.
这里 * 标识一个元素相关的乘积。对于层,是一个独立的伯努利随机变量的向量,其中每个伯努利随机变量都有为1的概率。对这个向量进行采样,并与该层的输出按元素顺序相乘, , 用于创建精简输出。之后这些精简输出会被用于下一层的输入,将这个过程应用到每个层。这相当于从一个较大的网络中采样了一个子网。
For learning, the derivatives of the loss function are backpropagated through the sub-network. At test time, the weights are scaled as as shown in Figure 2. The resulting neural network is used without dropout.
对学习过程,损失函数的导数在子网中反向传播,在测试时,权重值如图2所示成比例 ,最后得到的是没有使用dropout的神经网络。
-
Learning Dropout Nets 学习Dropout网络
Dropout neural networks can be trained using stochastic gradient descent in a manner similar to standard neural nets.
Dropout神经网络可以像用随机梯度下降的方式进行训练,
The only difference is that for each training case in a mini-batch, we sample a thinned network by dropping out units. Forward and backpropagation for that training case are done only on this thinned network.
唯一的不同是,对每个使用一个小批次的训练案例来说,我们通过丢弃神经元采样了一个精简的网络。向前和向后传播的训练用例只是在这个精简网络中完成了。
The gradients for each parameter are averaged over the training cases in each mini-batch. Any training case which does not use a parameter contributes a gradient of zero for that parameter.
每个参数的梯度都在每个小批次的训练案例中获取平均值,任何不使用参数的训练用例都为该参数贡献了一个梯度为零的值。
Many methods have been used to improve stochastic gradient descent such as momentum, annealed learning rates and L2 weight decay. Those were found to be useful for dropout neural networks as well.
许多方法被用来提升随机梯度下降,例如动量算法,退火学习率和L2权重衰减。这些被证明对于dropout神经网络来说同样是有效的。
One particular form of regularization was found to be especially useful for dropout— constraining the norm of the incoming weight vector at each hidden unit to be upper bounded by a fixed constant c.
一种特定的正则化方式被发现对dropout尤其有效:将每个隐藏单元的传入权值向量的范数限制为固定常数c的上界。
In other words, if represents the vector of weights incident on any hidden unit, the neural network was optimized under the constraint . This constraint was imposed during optimization by projecting w onto the surface of a ball of radius c, whenever w went out of it.
换而言之,如果 表示在任意隐藏神经元上的权值下降向量,神经网络在约束 下被进行优化。 通过将投影到半径为的球表面,只要离开该表面,就在优化过程中施加该约束。
This is also called max-norm regularization since it implies that the maximum value that the norm of any weight can take is c. The constant c is a tunable hyperparameter, which is determined using a validation set.
Max-norm regularization has been previously used in the context of collaborative filtering (Srebro and Shraibman, 2005). It typically improves the performance of stochastic gradient descent training of deep neural nets, even when no dropout is used.



