ac平台部署Stable Diffusion官方版本(无webui)
ac平台部署Stable Diffusion 记录
官方版本(无webui)
sd官方仓库 https://github.com/Stability-AI/StableDiffusion
环境配置
进入Eshell,加载pytorch dtk23.04环境
1 | module rm compiler/rocm/2.9 |
在登陆节点下载依赖
1 | pip install transformers==4.19.2 diffusers invisible-watermark |
下载官方仓库
1 | # 超算服务器无法正常访问github,该链接为官方仓库同步镜像 |
安装依赖
首先修改requirements.txt,否则会由于找不到合适版本的包无限循环
1 | #gradio==3.11 |
然后执行安装
1 | cd StableDiffusion. |
不出意外的话会成功安装,失败的话可能是网络原因,多尝试几次即可
+++
Xformers 加速注意力模块(可选)
(暂未实现)
+++
下载模型文件
1 | mkdir ckpt && cd ckpt |
包含的模型
1 | model: |
官方ckpt模型不包含vit和clip权重,正常情况下pretrain模型权重会自动从huggingface中进行缓存,但是超算计算节点是无法访问外部资源的,因此需要自己从huggingface下载,我选择的方式为在本地缓存之后上传。
在本机中clone仓库装完依赖,然后执行测试脚本,
1 | python scripts/txt2img.py --prompt "a professional photograph of an astronaut riding a horse" --ckpt ckpt/v2-1_512-ema-pruned.ckpt --config configs/stable-diffusion/v2-inference.yaml --H 256 --W 256 |
等待huggingface的模型缓存完毕,然后将本机~/.cache/huggingface/hub的models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K目录上传到超算的~/.cache/huggingface/hub目录中去。
运行sd
在用户目录新建一个作业脚本 sd.sh
1 |
|
执行该脚本
1 | sbatch sd.sh |
在Stable Diffusion目录下查看输出日志
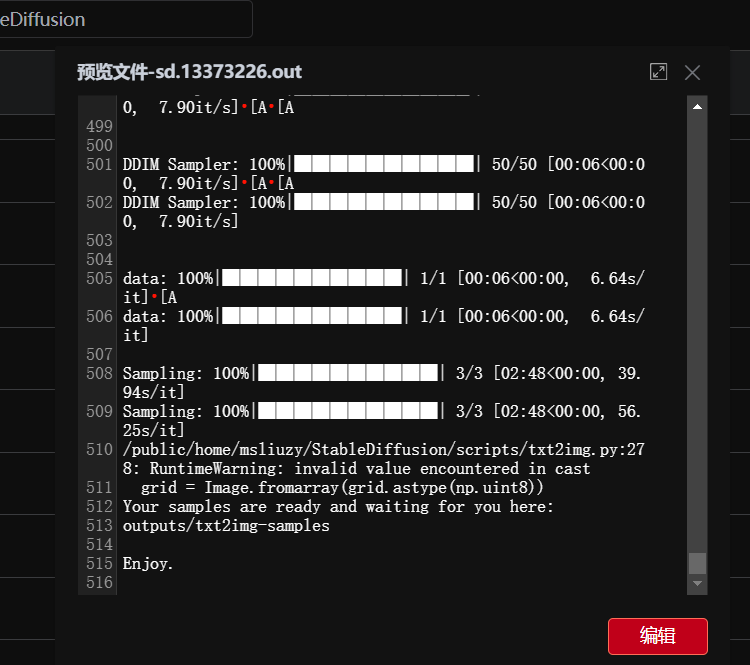
输出的结果位于 Stable Diffusion/outpus/txt2img-samples

已知问题
· 模型版本不能为v版,只能使用base版本的模型配置
· 待补充
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 阿伟又在打电动!
相关推荐
2023-09-18
ac平台部署Fooocus(Stable Diffusion非官方版本)
关于Fooocus fooocus是对 Stable Diffusion 的非官方开源实现,其可以轻松实现离线图像生成,并且部署十分方便。 https://github.com/lllyasviel/Fooocus/tree/main 下载和安装 进入Eshell,加载pytorch dtk23.04环境 123module rm compiler/rocm/2.9module load compiler/rocm/dtk-23.04module load apps/DeepLearning/PyTorch/1.13.1/pytorch-1.13.1-py3.9-dtk23.04 克隆官方仓库(这里同样是我自己创建的镜像仓库) 12git clone https://gitee.com/Cerber2ol8/Fooocus.gitcd Fooocus 克隆comfyUI的仓库 1234mkdir repositories && cd repositoriesgit clone https://gitee.com/Cerber2ol8/ComfyUI.gitmv C...
2023-03-22
3. A Survey on Generative Diffusion Model
生成扩散模型综述 摘要: 由于深度潜在表示,抽象-深度学习在生成任务中显示出卓越的潜力。生成模型是一类可以随机生成关于某些隐含参数的观察值的模型。近年来,扩散模型凭借其能量生成能力成为一种新兴的生成模型。如今,已经取得了巨大的成就。除了计算机视觉、语音生成、生物信息学和自然语言处理外,该领域还有待探索更多的应用。然而,扩散模型有其真正的缺点,即生成过程缓慢、数据类型单一、似然度低以及无法进行降维。它们正在导致许多改进工程。本文对扩散模型的研究现状进行了综述。首先,我们阐述了两个地标性作品DDPM和DSM以及一个统一地标性作品Score SDE的主要问题。然后,针对扩散模型领域存在的问题,提出了分类改进技术;为了提高模型的速度,本文提出了各种各样的先进技术来加速扩散模型——训练计划、免训练采样、混合建模以及得分和扩散统一。针对数据结构多样化问题,提出了在连续空间、离散空间和约束空间应用扩散模型的改进技术。对于似然优化,本文提出了改进ELBO和最小化变分差距的理论方法。对于降维问题,我们提出了几种解决高维问题的技术。对于现有模型,还根据具体的NFE提供了FID score、IS和NL...

2022-10-18
Novel AI元素法典
https://docs.qq.com/pdf/DZWdGeWtTdkhVYnVr
评论


